在实践中,尤其在需要数据回溯的场景下,许多 Flink 作业需要按顺序从多个数据源中读取数据:
- CDC:用户可以将数据快照存储在 HDFS/S3 ,数据的更新日志存储在数据库 binlog 或 Kafka 中
- 机器学习特征回填:当向模型中添加新特性时,需要从历史到现在的原始数据计算该特性。在大多情况下,历史数据和实时数据分别存储在两种不同的存储系统中,如 HDFS 和 Kafka
基本思路
在过去,如果要读取不同的数据源,用户必须运行两个不同的 Flink 作业:
- 基于不同连接器的代码实现,多个源之间的切换很复杂。在切换前控制上游 source 的具体状态,以及下游 source 如何获取上游的状态转换为初始状态。
- 目前还没有有效的机制来支持历史数据和实时数据之间平滑的迁移。平滑迁移需要定义切换的规则和时间,以确保数据的完整性和一致性。
为了平滑的支持对两种数据源的读取,Flink 作业需要先从 HDFS 读取历史数据,然后切换至 Kafka 读取实时数据,所以需要引入一个建立在 FLIP-27 之上的 混合 Source API。
hybrid source 包含具体 source 列表,hybrid source 按照定义顺序读取每个 source 的数据。当 A source 读取之后,切换到下一个 B souce :
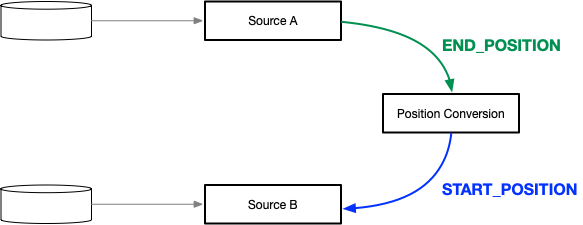
- 当前 source 的 splitEnumerator 提供读取 end position
- 下一个 source 支持设置 start position
- 用户提供自定义函数:将当前 source 的 end position 转换为下一个 source 的 start position
使用示例
HybridSource 内部切换示例: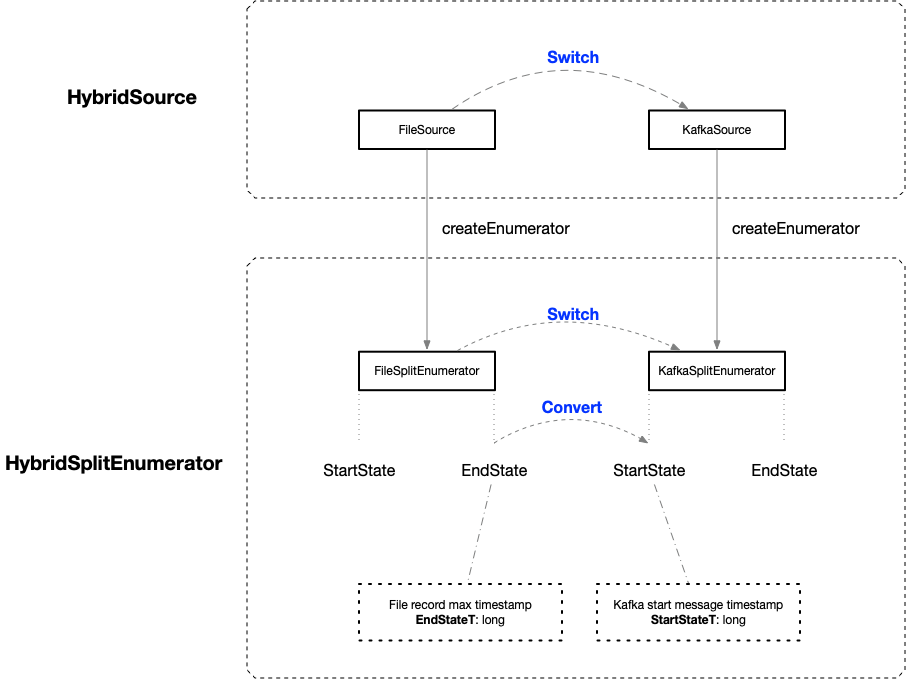
FileSource 串 KafkaSource ,Kafka 从指定位点开始消费:
1 | FileSource<String> fileSource = |
更复杂的示例,从前一个 source 获取 Kafka 的启动位点:
1 | HybridSource<String> hybridSource = |
代码实现
HybridSource
HybridSource 是基于责任链设计模式实现的。
1 | public class HybridSource<T> implements Source<T, HybridSourceSplit, HybridSourceEnumeratorState> { |
其中还包括以下几个函数式接口:
- SourceFactory :创建具体 source 的工厂类
1 | public interface SourceFactory<T, SourceT extends Source<T,?,?>, FromEnumT extends SplitEnumerator> extends Serializable { |
- SourceSwitchContext
1 | public interface SourceSwitchContext<EnumT> { |
- HybridSourceBuilder
1 | public static class HybridSourceBuilder<T, EnumT extends SplitEnumerator> { |
- HybridSourceTest
演示构建一个 HybridSource
1 |
|
HybridSourceSplitEnumerator 与 HybridSourceReader 交互流程: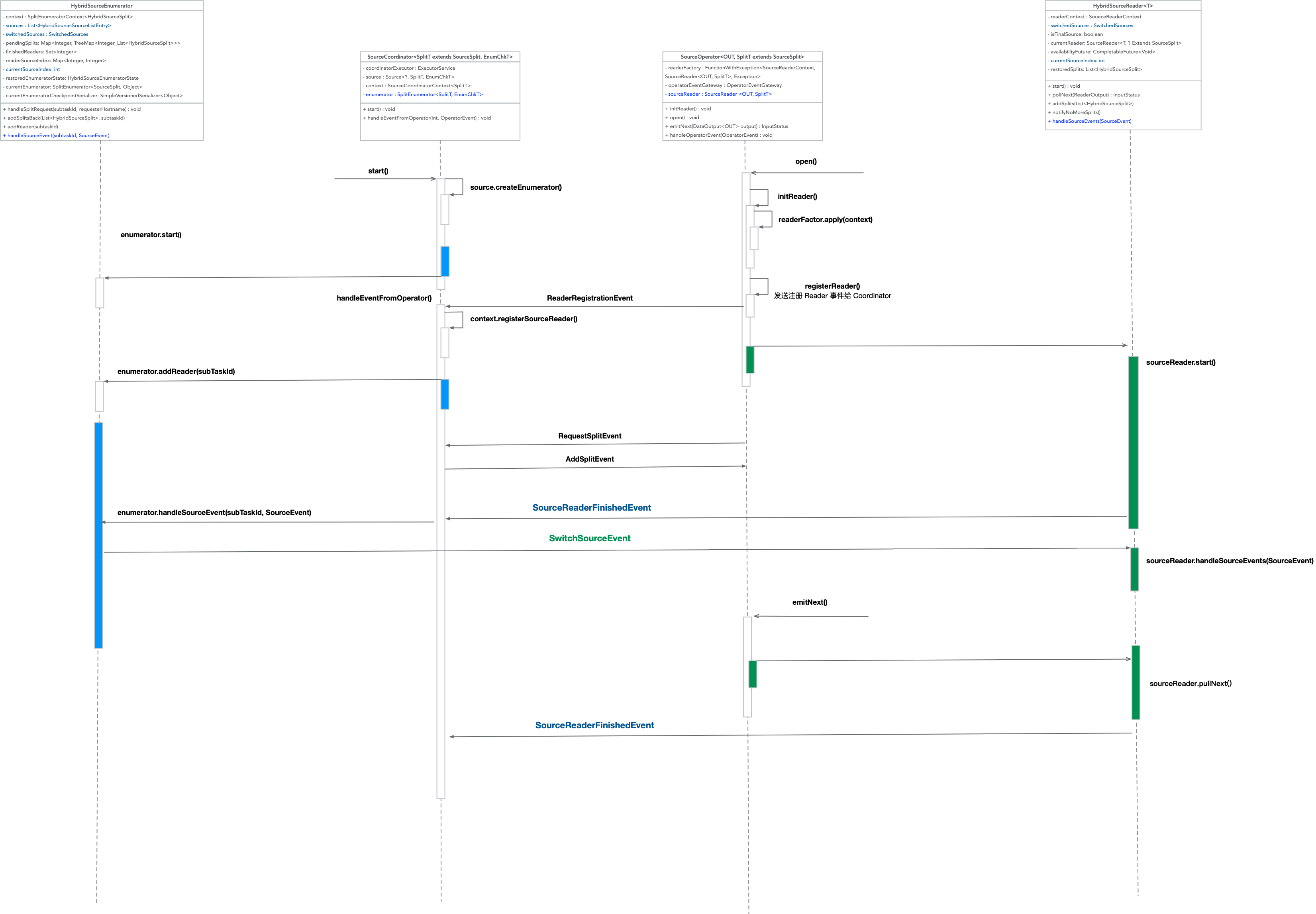
HybridSourceSplitEnumerator
1 | public class HybridSourceSplitEnumerator |
HybridSourceReader
1 | public class HybridSourceReader<T> implements SourceReader<T, HybridSourceSplit> { |
参考
FLIP-150: Introduce Hybrid Source
Flink–Hybrid Source提出的动机及实现原理介绍
FLIP-150 讨论列表