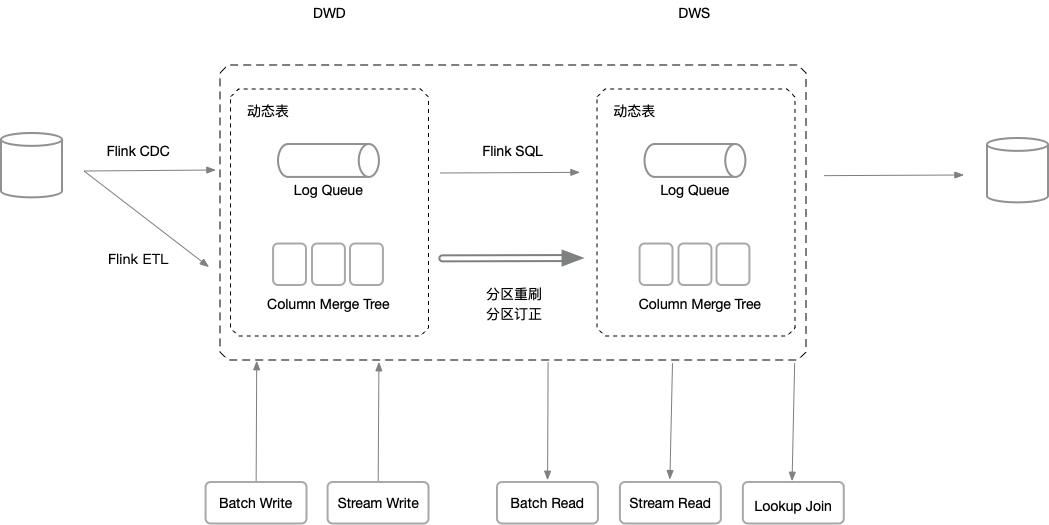
动态表:全新的 Flink 内置存储。
Flink Dynamic Table 可以理解为一套流批一体的存储,并无缝对接 Flink SQL 。原来 Flink 只能读写像 Kafka 、 HBase 这样的外部表,现在用一套 Flink SQL 语法就可以像原来创建源表和目标表一样,创建一个 Dynamic Table。流式数仓的分层数据可以全部放到 Flink Dynamic Table 中,通过 Flink SQL 就能实时地串联起整个数仓的分层,既可以对 Dynamic Table 中不同明细层的数据做实时查询和分析,也可以对不同分层做批量 ETL 处理。
最终,利用 Flink CDC 、Flink SQL 、Flink Dynamic Table 就可以构建一套完整的流式数仓,实现实时离线一体化的体验。
目前,作为一个独立的开源项目 flink-table-store 开发中,该功能预计在 Flink 1.15 中发布。
基本思路
生产应用中,用户倾向于使用 Kafka 存储 logs ,使用 hudi/iceberg/click 作为一张表。FLIP-188 提议引入一种内置的存储:动态表,从 Flink SQL 视角,真正统一 changelog&table 实现,未来也可以支持点查。
内置存储有以下几个特点:
- Flink SQL 的内置存储
- 改善可用性问题
- Flink DDL 不再是数据源的简单映射,而是真正创建表
- 屏蔽和抽象底层技术细节,去除连接 connector 需要填写的 options ,使 SQL 聚焦于业务逻辑本身
- 支持亚秒级写入和消耗
- 可以通过面向服务的消息队列(如 Kafka)支持
- 高吞吐的 scan 能力
- 使用 columnar 格式的文件系统,同 iceberg/hudi 一样
- 还需要自动处理各种 Insert/Update/Delete 操作和表定义
- 接收任何类型的变更日志
- 接收任何类型的数据类型
- 表可以有主键,也可以没有主键
存储结构
从数据结构上看, Dynamic Table 内部有两个核心组件,File Storage 和 Log Storage :
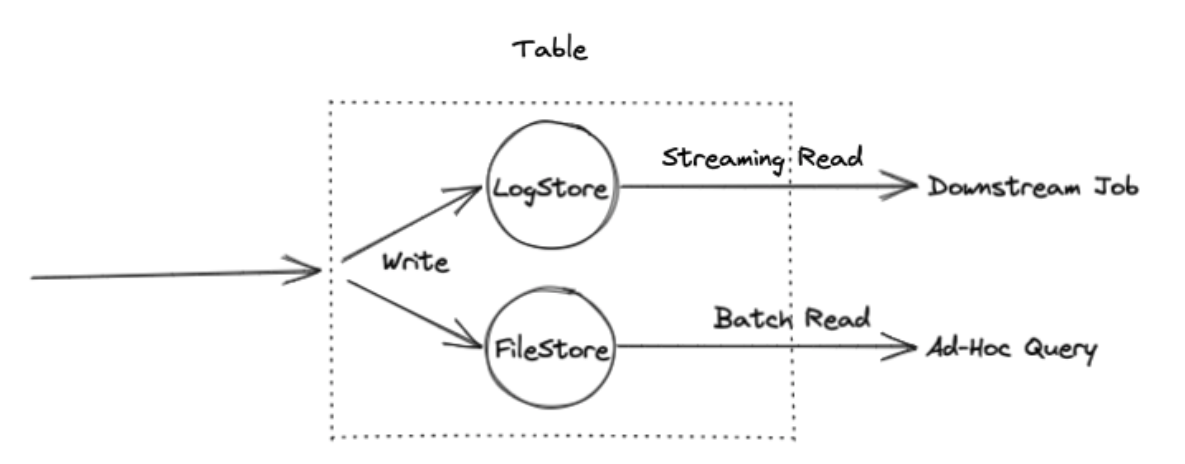
File Storage
Table 的文件存储形式,采用 LSM 架构,支持流式的更新、删除、增加等。采用开放的列存结构,支持压缩等优化。对应 Flink SQL 的批模式,支持全量批式读取。
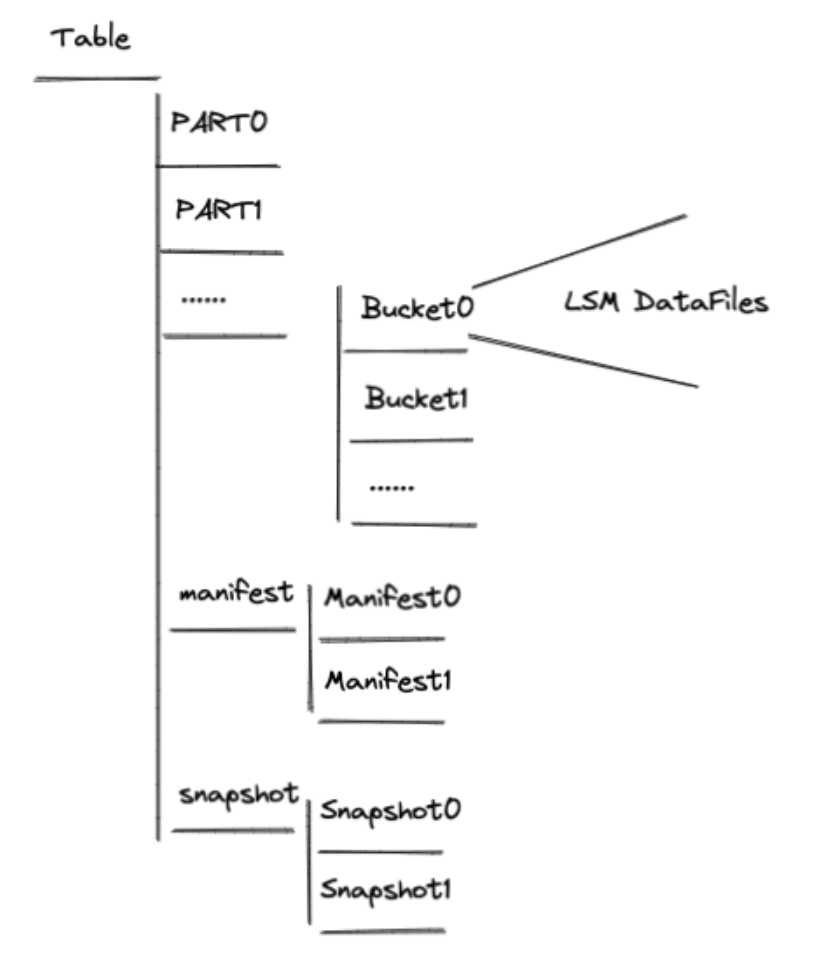
- Data 目录
- Part 目录:partition,在 DDL 中以 “PARTITIONED BY” 定义,同 Hive 一样,如 “dt=2022-03-12”
- Bucket 目录:partition 下的 bucket ,数据通过 hash 落入 bucket ,分桶对应一个由多个 files 组成的 LSM
- LSM datafiles:数据文件,抽象 format,支持 orc、parquet、avro ,record schema 如下:
SequenceNumber
ValueKind(add or delete)
RowData: key
RowData: value
- Meta 文件
Manifest file: 代表多少 files 已经 added ,多少 files 已经 deleted,代表 table 的一次变更,Manifest 记录增量文件的版本,schema 如下:
data file 名称
FileKind: delete 或 add
partition
bucket
min/max key: 用于 skipping
min/max sequenceNumber
统计数据:data file 大小,行数Snapshot file: manifest files 集合,代表 table 的一个 snapshot 。snapshot 代表一个版本的所有 files ,snapshot file 的 schema 是一个 Manifest:
manifest file名称
lower/upper partition: 用于分区裁剪
统计数据:manifest file 大小,added file 个数,deleted file 个数
table path 文件夹
1
2
3
4
5
6
7
8staff@localhost:/var/folders/px/n0m4_bp13077qbk54k30yy340000gp/T/junit1120128347261300405/junit4490023537149085262$ ll
total 0
drwx------ 6 staff staff 192 3 11 17:55 ./
drwx------ 3 staff staff 96 3 11 17:51 ../
drwxr-xr-x 5 staff staff 160 3 11 17:55 manifest/
drwxr-xr-x 4 staff staff 128 3 11 17:55 p=p1/
drwxr-xr-x 4 staff staff 128 3 11 17:55 p=p2/
drwxr-xr-x 3 staff staff 96 3 11 17:55 snapshot/分区 p1、分桶 bucket-1
1
2
3
4
5
6
7
8
9
10
11
12staff@localhost:/var/folders/px/n0m4_bp13077qbk54k30yy340000gp/T/junit1120128347261300405/junit4490023537149085262/p=p1$ ll
total 0
drwxr-xr-x 4 staff staff 128 3 11 17:55 ./
drwx------ 6 staff staff 192 3 11 17:55 ../
drwxr-xr-x 3 staff staff 96 3 11 17:57 bucket-1/
drwxr-xr-x 3 staff staff 96 3 11 17:57 bucket-2/
staff@localhost:/var/folders/px/n0m4_bp13077qbk54k30yy340000gp/T/junit1120128347261300405/junit4490023537149085262/p=p1/bucket-1$ ll
total 8
drwxr-xr-x 3 staff staff 96 3 11 17:57 ./
drwxr-xr-x 4 staff staff 128 3 11 17:55 ../
-rw-r--r-- 1 staff staff 426 3 11 17:55 sst-90911871-51d6-4323-aa55-f25c8a29021d-0manifest 目录
1
2
3
4
5
6
7staff@localhost:/var/folders/px/n0m4_bp13077qbk54k30yy340000gp/T/junit1120128347261300405/junit4490023537149085262/manifest$ ll
total 24
drwxr-xr-x 5 staff staff 160 3 11 17:55 ./
drwx------ 6 staff staff 192 3 11 17:55 ../
-rw-r--r-- 1 staff staff 2681 3 11 17:55 manifest-5a53de30-1d30-43f0-a837-078ca61e0b93-0
-rw-r--r-- 1 staff staff 837 3 11 17:55 manifest-list-0267739b-40f7-4c33-b433-d8f73b50af17-0
-rw-r--r-- 1 staff staff 931 3 11 17:55 manifest-list-0267739b-40f7-4c33-b433-d8f73b50af17-1snapshot-1
1
2
3
4
5staff@localhost:/var/folders/px/n0m4_bp13077qbk54k30yy340000gp/T/junit1120128347261300405/junit4490023537149085262/snapshot$ ll
total 8
drwxr-xr-x 3 staff staff 96 3 11 17:55 ./
drwx------ 6 staff staff 192 3 11 17:55 ../
-rw-r--r-- 1 staff staff 283 3 11 17:55 snapshot-1
1 | { |
Log Storage
Table 的操作记录,是一个不可变更序列,对应 Flink SQL 的流模式,可以通过 Flink SQL 订阅 Dynamic Table 的增量变化做实时分析,支持插件化实现。
依赖 Kafka 作为底层存储,Log Storage 中的 bucket 就对应 Kafka Partition 。
源码阅读准备
flink git仓库 切换到 master 分支,当前是 1.15-SNAPSHOT 分支,需要 install 到本地,flink-table-store 需要引用这个版本。
flink-table-store git仓库,切换到 master 分支。
FileStoreITCase
- 分区表
测试数据集:
0,p1,1
0,p1,2
5,p1,1
6,p2,1
3,p2,5
5,p2,1
buckets = 3
partitions {1}
keys {2}
中间结果:
partition -> p1
key -> 1
row -> 0,p1,1
partition -> p1
key -> 1
row -> 5,p1,1
partition -> p2
key -> 1
row -> 6,p2,1
partition -> p2
key -> 1
row -> 5,p2,1
partition -> p1
key -> 2
row -> 0,p1,2
partition -> p2
key -> 5
row -> 3,p2,5
输出结果:
5,p2,1
3,p2,5
5,p1,1
0,p1,2
- 非分区表
测试数据集:
0,p1,1
0,p1,2
5,p1,1
6,p2,1
3,p2,5
5,p2,1
buckets = 3
keys {2}
key -> 1
row -> 0,p1,1
key -> 1
row -> 5,p1,1
key -> 1
row -> 6,p2,1
key -> 1
row -> 5,p2,1
key -> 2
row -> 0,p1,2
key -> 5
row -> 3,p2,5
输出结果:
5,p2,1
0,p1,2
3,p2,5
写流程
- LSM 处理(类似 Leveldb)
- 在内存中维护 memtable ,数据直接写入 memtable ,每条数据都有一个 sequenceNumber 。对于相同的 key ,最大 sequenceNumber 的 key 将会覆盖小 sequenceNumber
- 当 memtable 已满或 PrepareCommit ,执行刷盘,按 key + sequenceNumber 排序,合并重复的 key ,使用特殊的 format 将数据写入 remote file
- 异步线程执行 LSM compactions
- PrepareCommit
- 刷写 memtable
- 提交信息:DeleteFiles 、AddFiles
- Global Commit
- 读取旧 snapshots ,如果 checkpoint 已提交,则返回
- 读取前一个 snapshot-{i} ,将 buckets 的 deleteFiles 和 addFiles 写入新的 manifest ,生成一个新的 snapshot-${i+1}
读取流程
- Planner
- 读取当前的 snapshot ,根据过滤条件裁剪分区,获得需要读取的 manifests
- 为每个 partition 中的每个 bucket ,合并 manifests 中的 deleteFiles 和 addFiles ,生成一个 file list
- SplitEnumerator
- 遍历需要读取的 partitions ,为每个 bucket 生成相应的 SourceSplit
- 根据过滤条件过滤出 bucket 中需要读取的 files ,在 SourceSplit 生成一个 LSM 层
- Runtime Task
- 获得要读取的 SourceSplit ,生成 LSM 的 MergeIterator ,并读取数据
几个关键类图
FileStore 类图
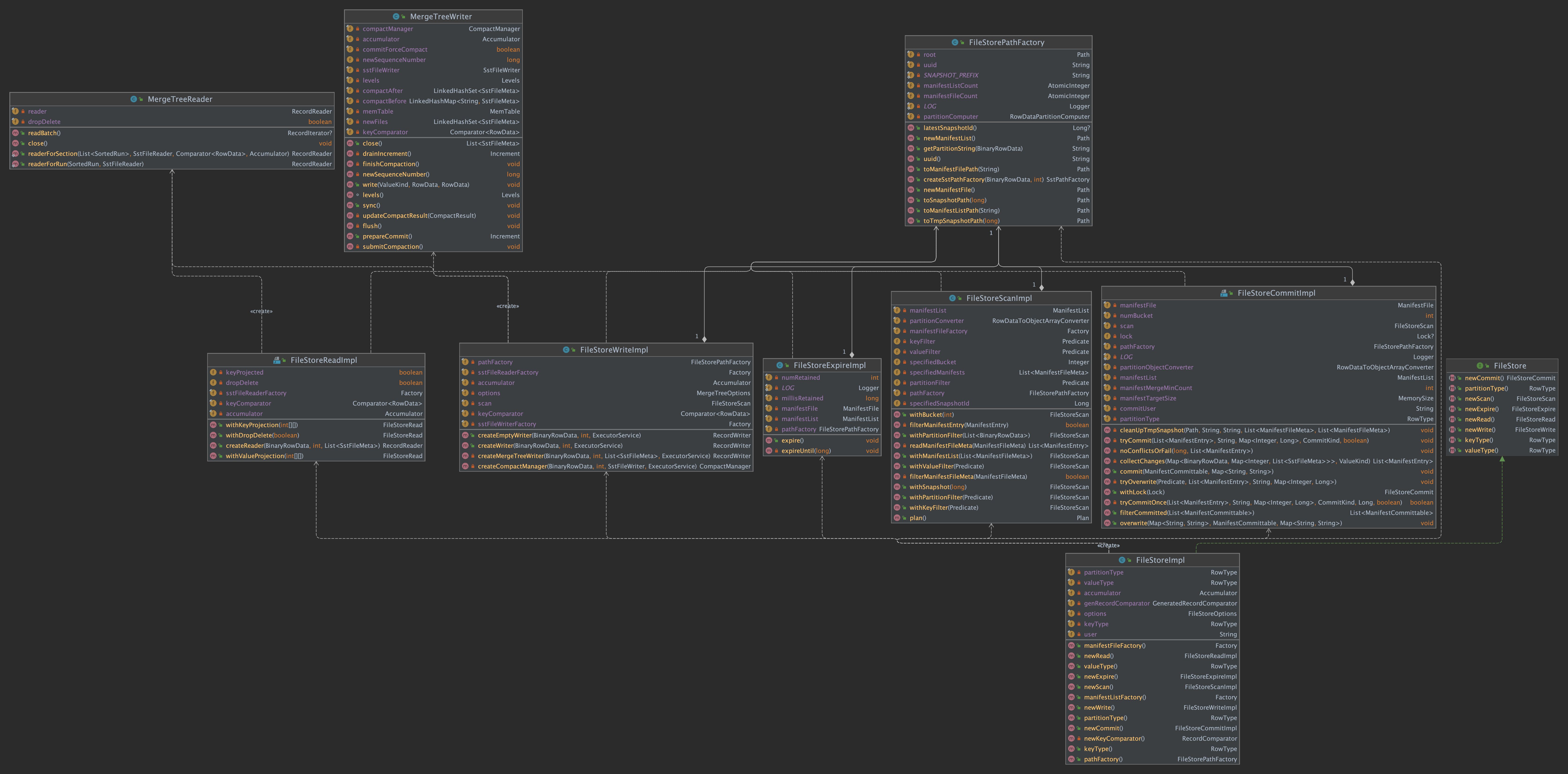
FileStoreSource 类图
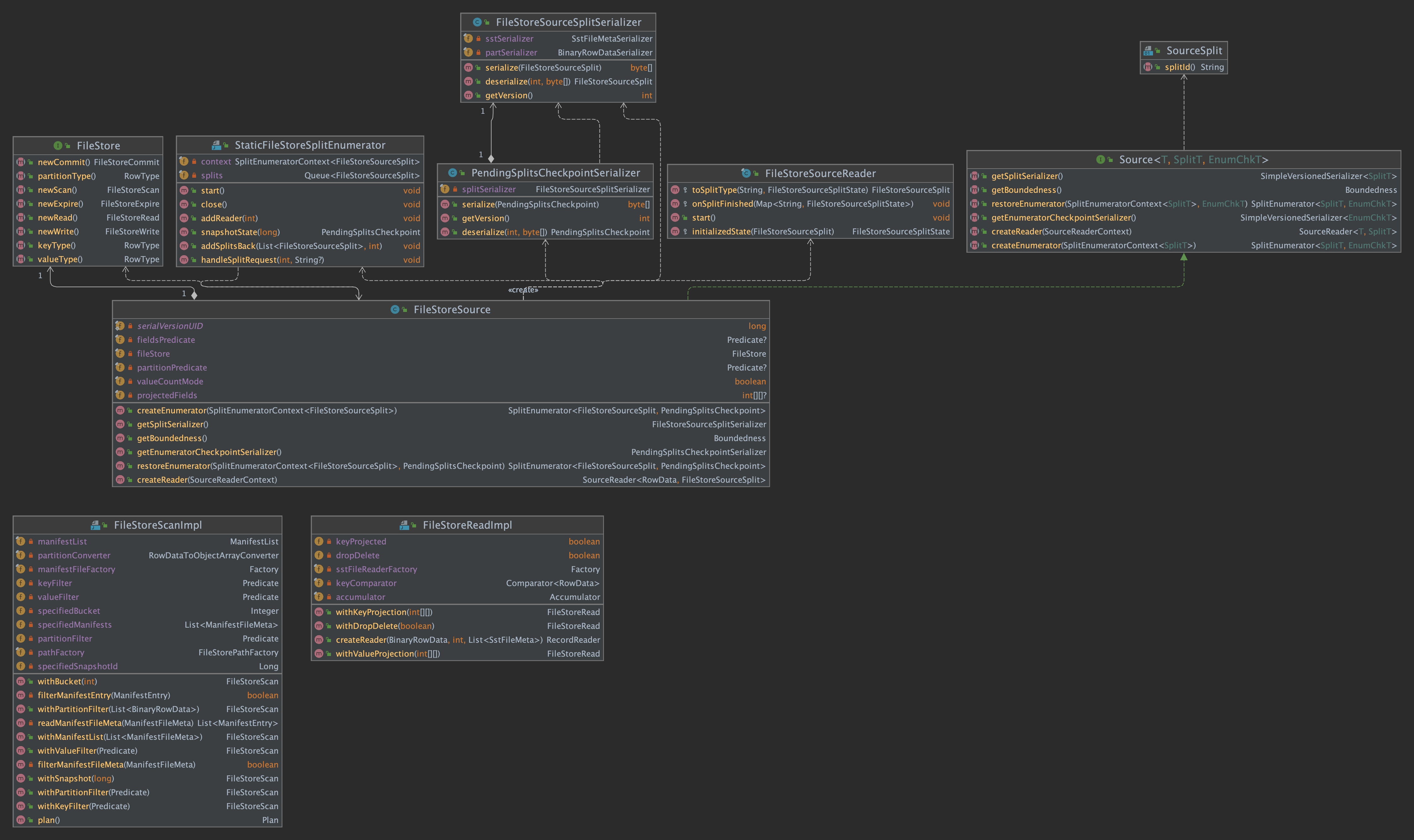
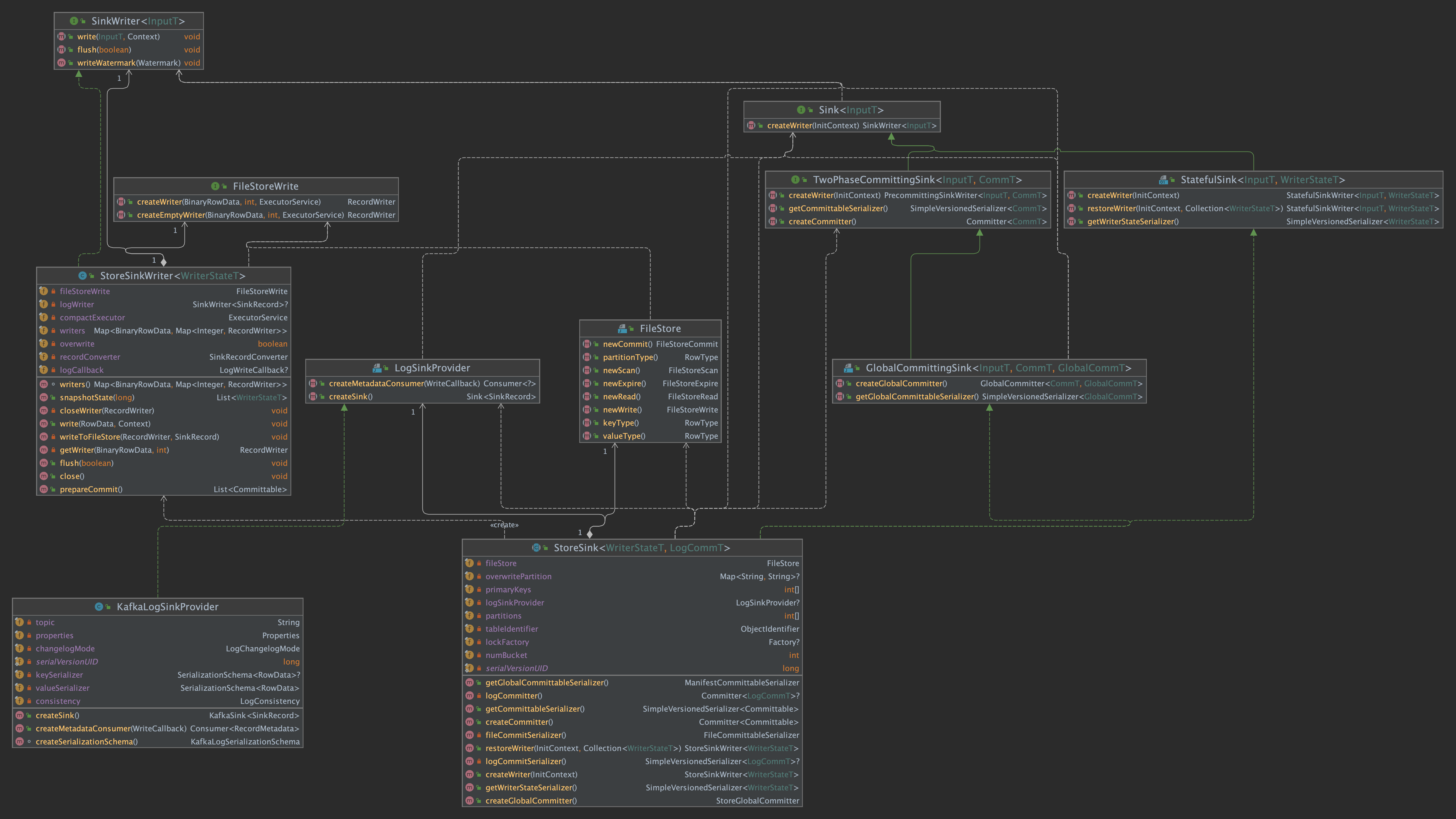
StoreSink 类图
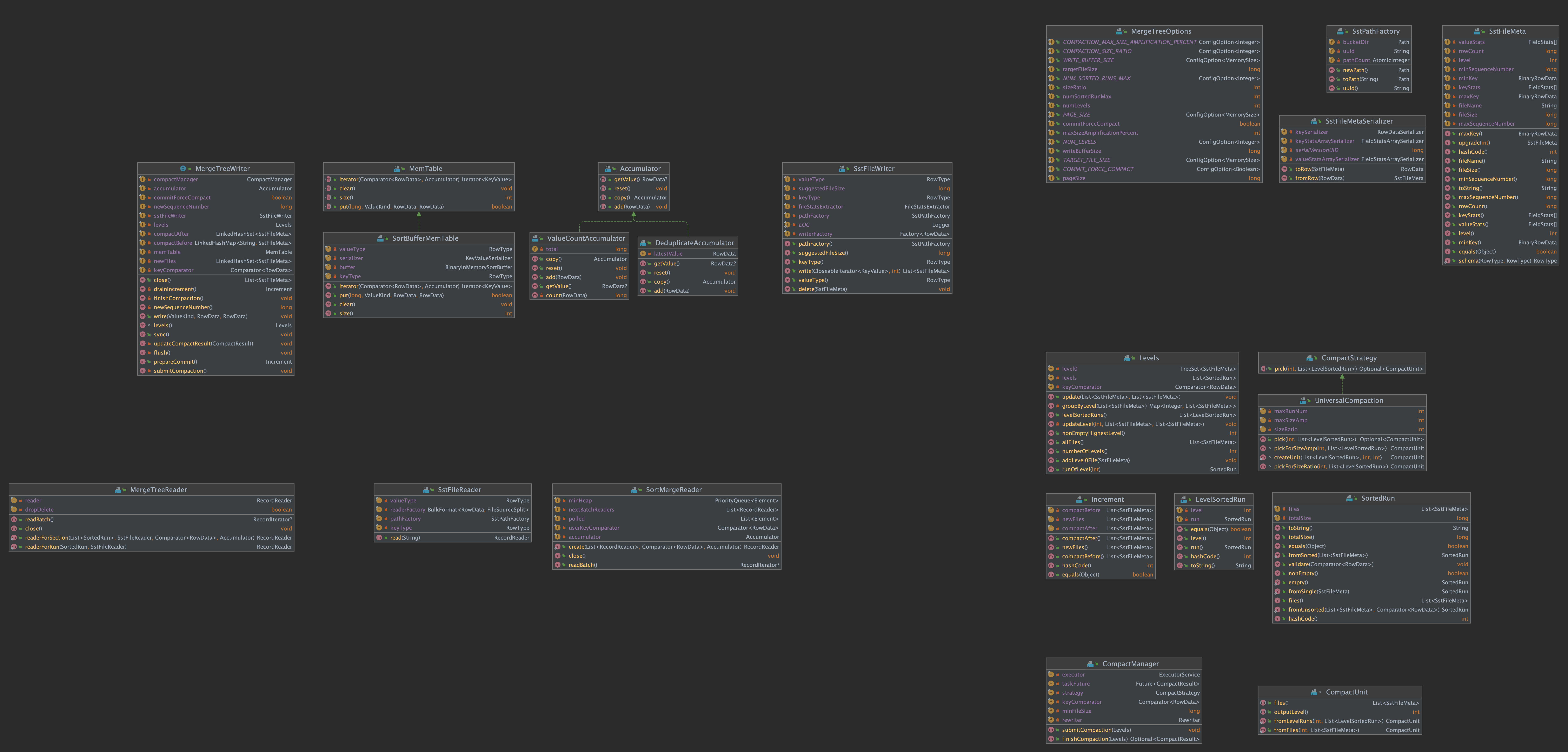
mergetree 包类图
KafkaLogStore类图
在 flink-table-store/flink-table-store-kafka/src/main/resources/META-INF/services 路径上有一个文件 org.apache.flink.table.factories.Factory 中定义了 KafkaLogStoreFactory ,用 SPI 机制来实现 flink-table-store 的 LogStoreTableFactory 。
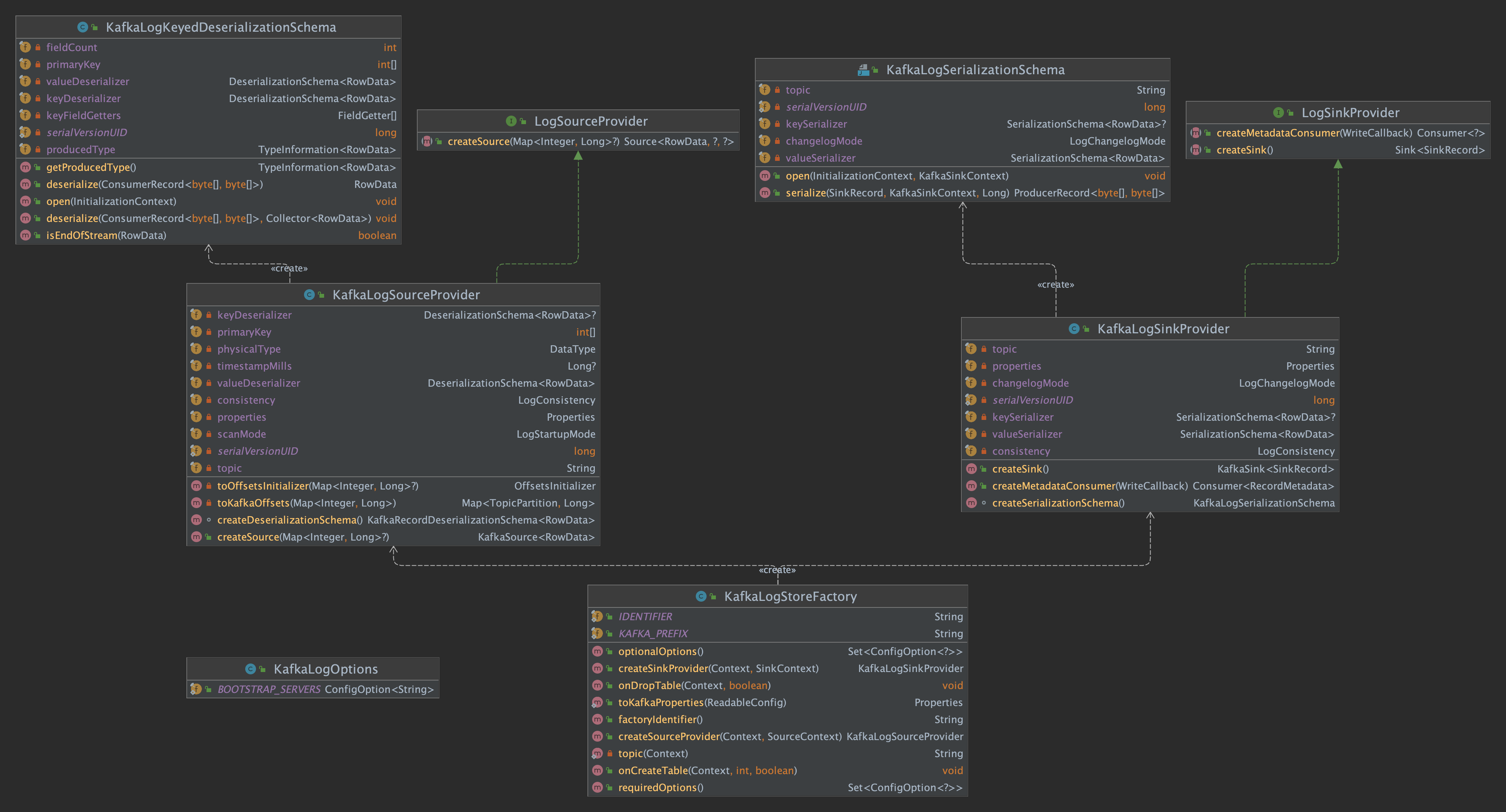
KafkaLogSourceProvider
1 | public class KafkaLogSourceProvider implements LogSourceProvider { |
KafkaLogSinkProvider
1 | public class KafkaLogSinkProvider implements LogSinkProvider { |
Demo
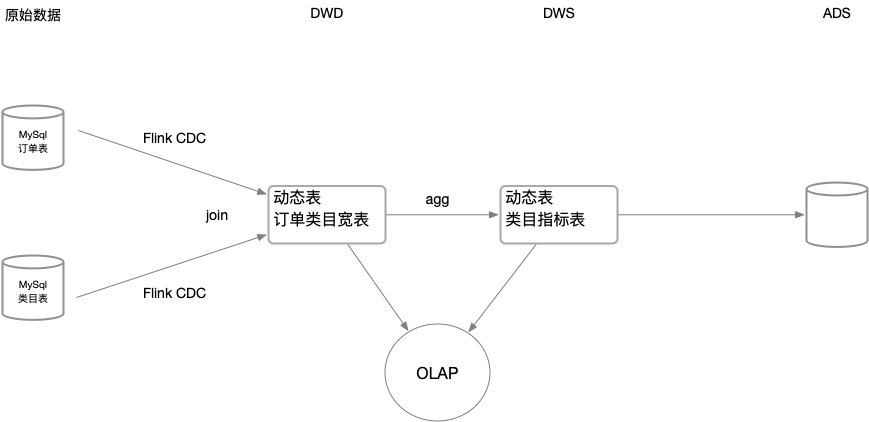
Stream
- MySql CDC : 订单表
1 | CREATE TEMPORARY TABLE orders ( |
- MySql CDC : 类目表
1 | CREATE TEMPORARY TABLE cate_dim ( |
- Flink 动态表:DWD 订单类目宽表
创建动态表的 DDL ,不用再指定 connector options ,就像在离线平台创建表一样,只需要指定表字段、主键、分区即可。
1 | CREATE TEMPORARY TABLE dwd_orders_cate ( |
- Flink 动态表:DWS 类目指标聚合表
1 | CREATE TABLE dws_cate_day ( |
- 流作业:两张 MySql CDC 表 join 写入 DWD
1 | INSERT INTO dwd_orders_cate |
- 流作业:DWD 经过聚合写入 DWS
1 | INSERT INTO dws_cate_day |
OLAP
- 实时 OLAP:join 订单宽表和类目指标表,得出订单在这个类目下金额的占比
1 | SELECT |
- 历史 OLAP:查询订单宽表三天前的数据
1 | SELECT * FROM dwd_orders_cate WHERE dt = '2021-12-05'; |
Batch
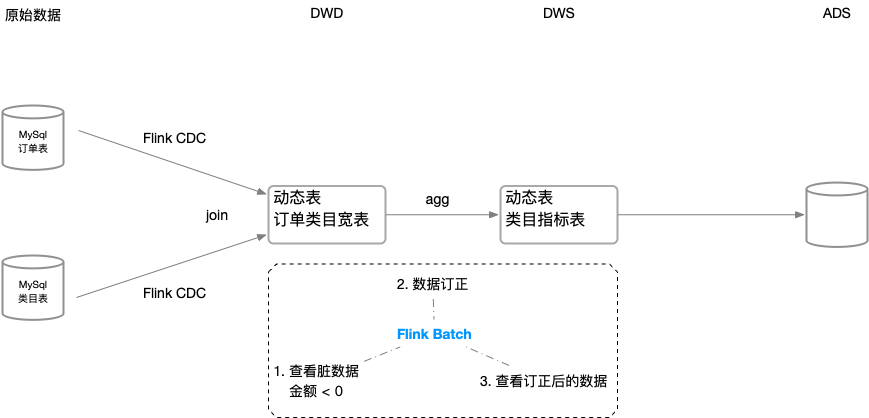
- Batch 数据订正:覆写指定分区
1 | INSERT OVERWRITE dws_cate_day PARTITION (dt = '2021-12-05') |
依赖
Flink 要统一存储,就必须要提供高质量的查询服务,如 OLAP 交互查询,这其中包括 Flink SQL 在 OLAP 交互场景下的优化、动态表存储性能和一致性的优化以及构建动态表服务化能力等诸多工作。
参考
FLIP-188: Introduce Built-in Dynamic Table Storage
FLIP-188 讨论列表
Apache Flink 不止于计算,数仓架构或兴起新一轮变革
Flink Table Store:流批一体存储
基于 Apache Flink Table Store 的全增量一体实时入湖
Apache Flink Table Store 0.2.0 发布
Flink Table Store 典型应用场景
Apache Flink Table Store 0.3.0 Release Announcement
Flink Table Store 0.3 构建流式数仓最佳实践
快速体验 Flink Table Store 入门