Zeppelin 是基于 Web 的交互式数据分析 notebook ,支持 SQL 、 Scala 、 Python 等语言。
Zeppelin 通过插件化的 Interpreter 来解析用户提交的代码,并将其转化到对应的后端(计算框架、数据库等)执行,支持 angular 、beam 、 bigquery 、cassandra 、es 、HBase 、 influxdb 、Flink 、Spark 等引擎。
本机搭建一个 Zeppelin 环境,方便在界面上写简单的代码或 sql 进行测试任务。
本机安装
- zeppelin 启动命令:
1 | bin/zeppelin-daemon.sh start |
本机会启动一个 ZeppelinServer 进程
- zeppelin 停止命令:
1 | bin/zeppelin-daemon.sh stop |
- 访问入口:
1 | http://localhost:8080 |
- 也可以以服务形式启动 zeppelin :
1 | sudo service zepplin start |
1 | bin/zeppelin-daemon.sh upstart |
docker 安装
- 拉取 docker 镜像:
1 | docker pull apache/zeppelin:0.10.0 |
- 启动 docker 镜像,–name 指定容器名称,-p 指定暴露的端口:
1 | docker run -d --name zeppelin0.10.0 -p 8888:8080 apache/zeppelin:0.10.0 |
Flink with Zeppelin
- 启动 flink
1 | cd $FLINK_HOME |
在 Zeppelin 界面上设置 FLINK_HOME
需要修改以下几个配置项: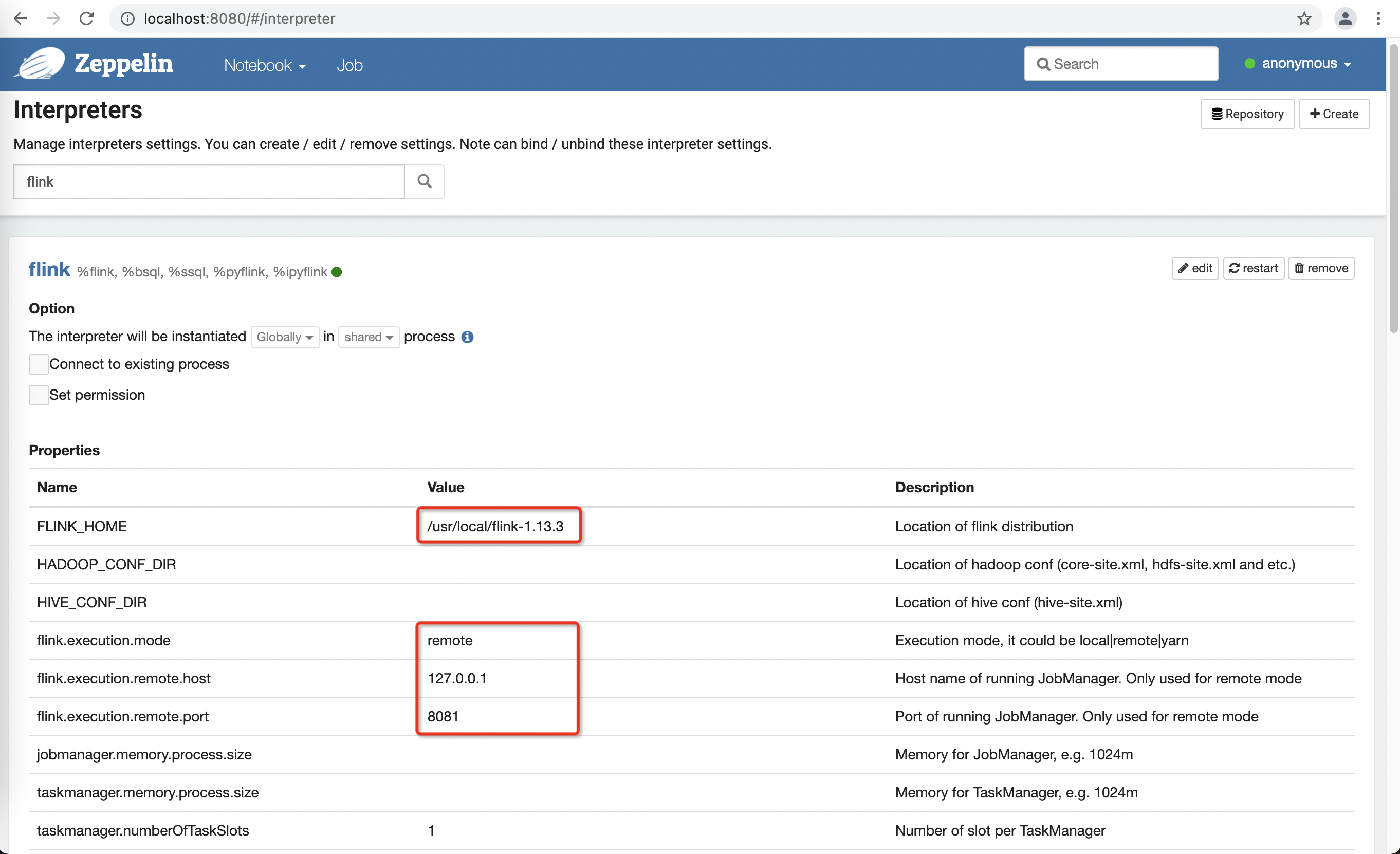
使用 Zeppelin 自带的 Flink tourial 脚本测试
%flink- 创建 scala environment%flink.pyflink- 提供 python environment%flink.ipyflink- 提供 ipython environment%flink.ssql- 提供 stream sql environment%flink.bsql- 提供 batch sql environment
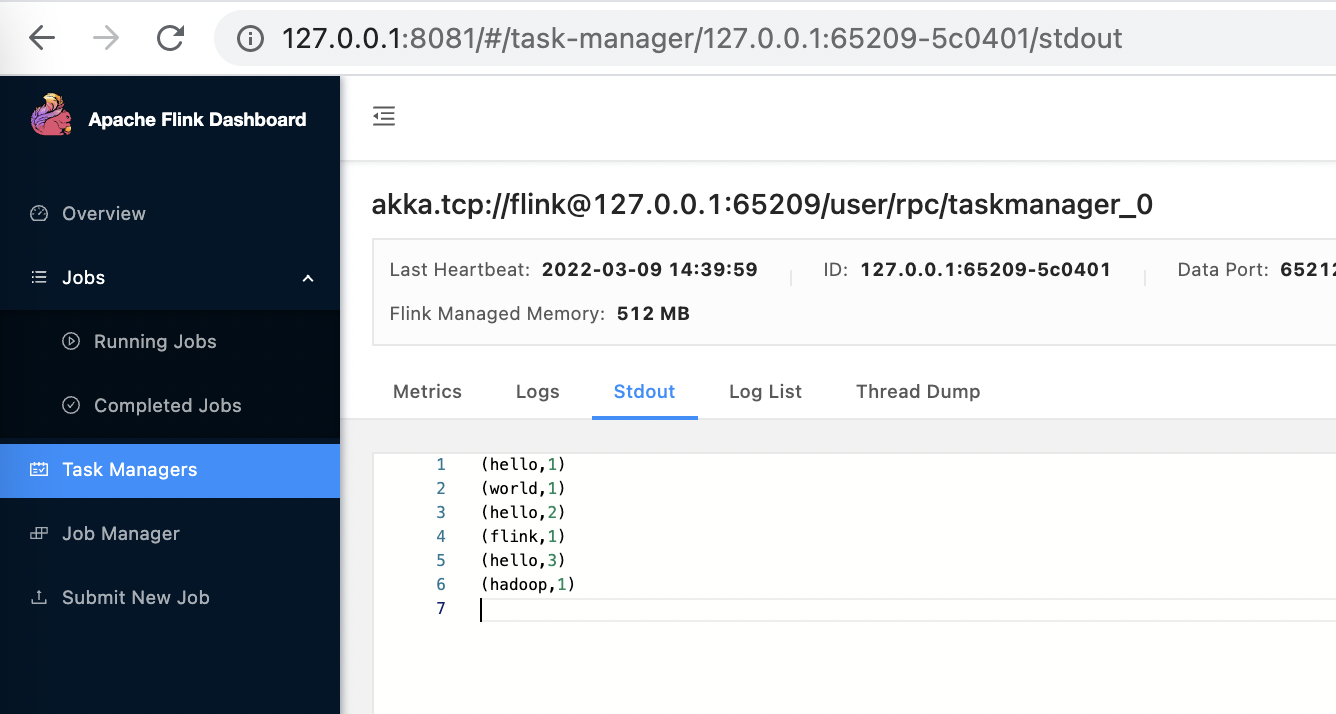
执行脚本测试,会启动 RemoteInterpreterServer 进程
- Batch WordCount
1 | %flink |
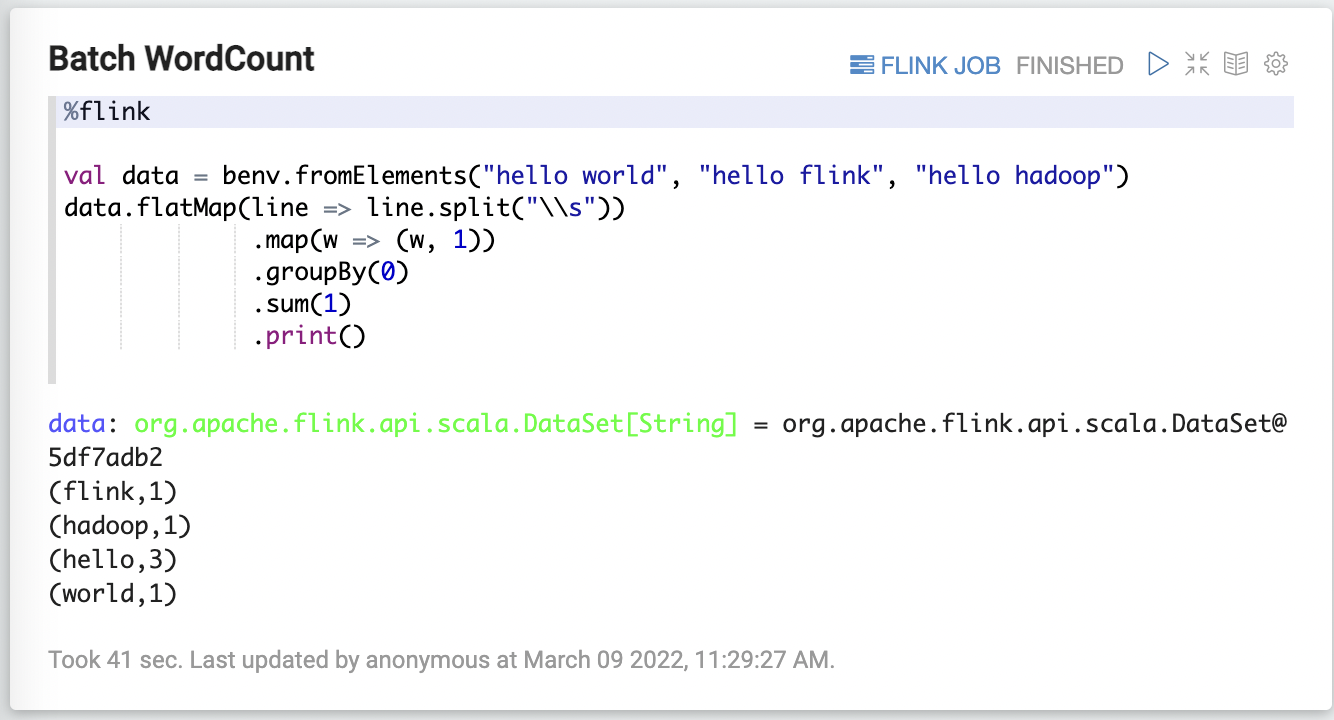
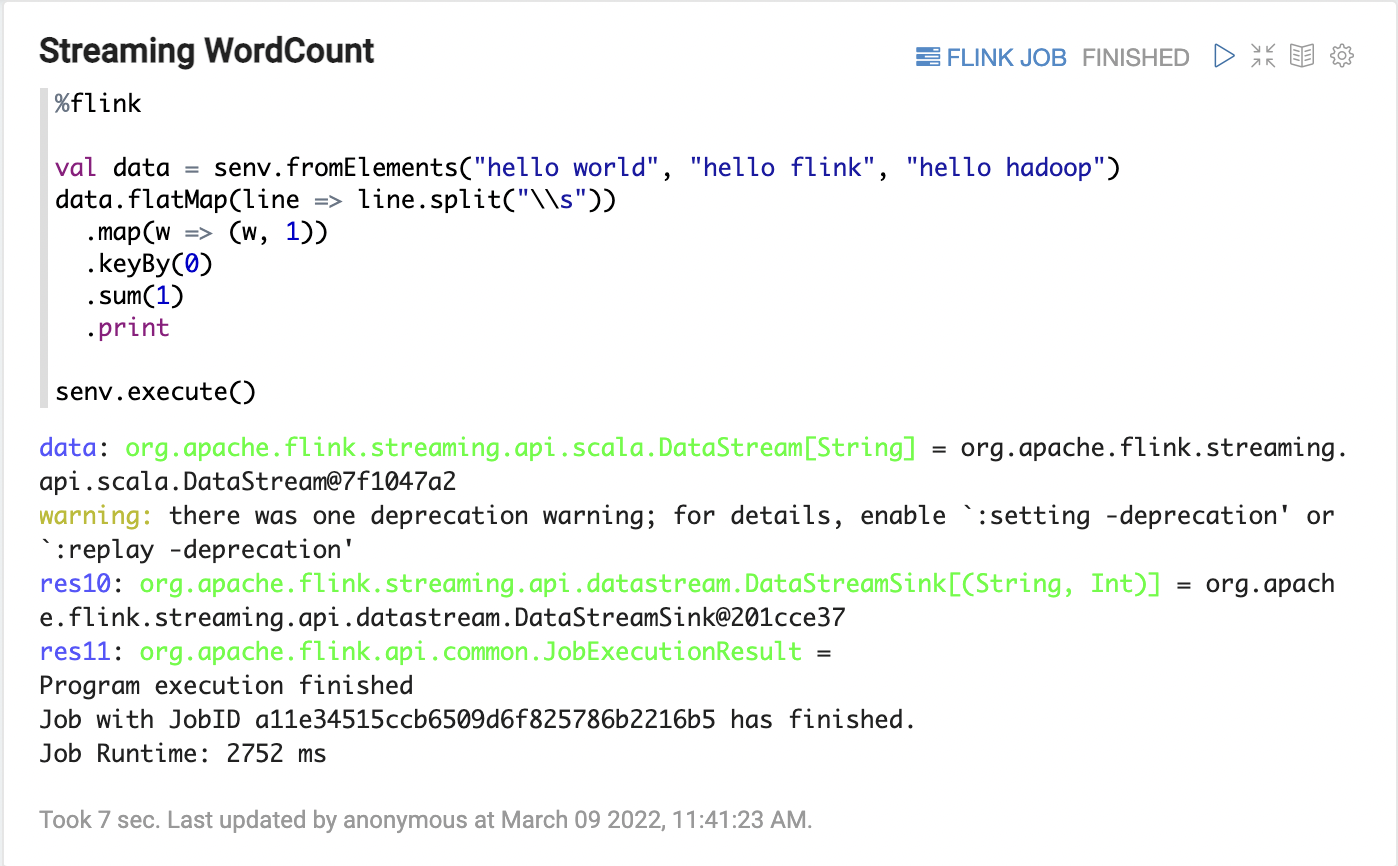
- Streaming WordCount
1 | %flink |