Flink 和 Hudi 的集成使用。
在查询时确认数据的 Schema ,湖存储成本低、灵活性高,非常适用于各种查询场景的中心化存储;
基于云服务兴起及成熟的对象存储,在云上构建存算分离的架构;
通过快照隔离,实现基础的 ACID 事务;
对接不同的查询引擎,实现各自的查询分析场景,实现湖仓一体的架构;
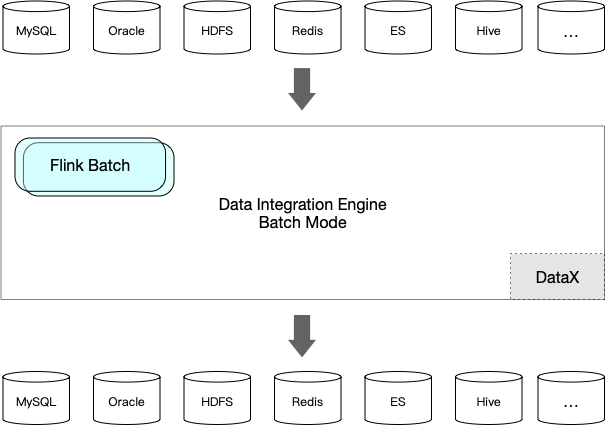
数据集成场景
- Batch Mode
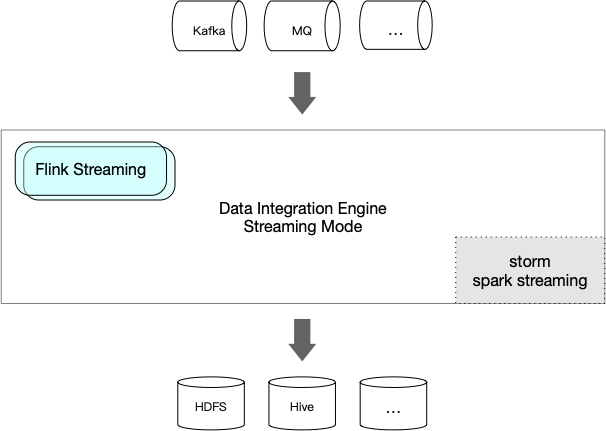
- Streaming Mode
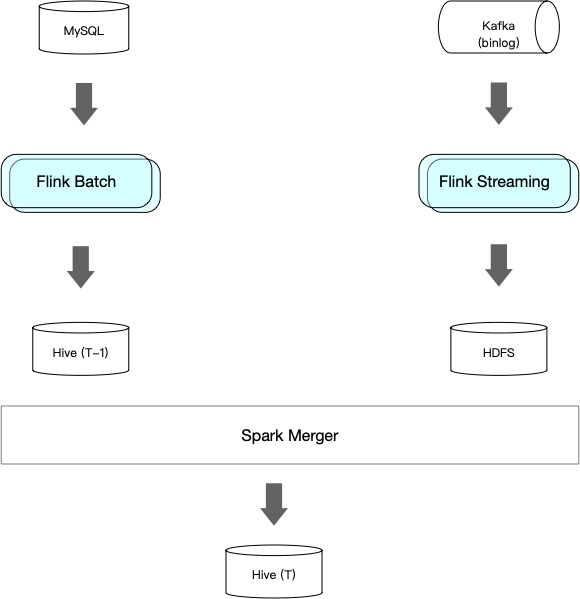
- Incremental Mode
- 批流一体解决方案
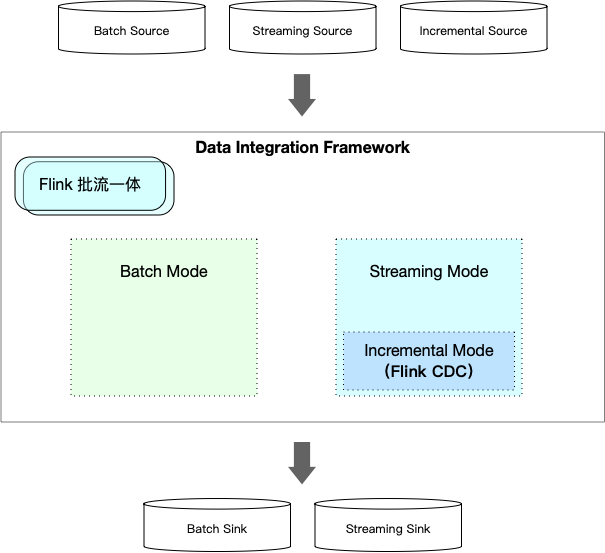
可以看出,借助 Flink 引擎的批流统一,将增量模式合并到流式模式中,摆脱对 Spark 的依赖,数据集成平台可以逐步实现计算引擎层的批流统一,同时实现批式、流式、增量三种数据集成场景。
在增量模式上,提供和流模式相当的数据延迟,赋予用户近实时分析的能力,进一步提高效率和降低计算成本:
流处理管道面向行处理提供秒级处理延迟,增量管道中面向列处理应该也提供相同的延迟,支持高效的 upsert 和查询能力。
基础概念
Hudi 是 Hadoop Updates and Incrementals 的简写,是由 Uber 开发并开源的 Data Lakes 解决方案。
它的设计目标是基于 Hadoop 兼容的文件系统(如 HDFS、S3 等),重度依赖 Spark 的数据处理能力来实现增量处理和丰富的查询能力。
Hudi 可以作为 Source、Sink ,它把数据存储到分布式文件系统(如 HDFS)中。
Hudi 有自己的数据表,从而具备将 Hudi 的 Bundle 整合进 Hive、Spark、Presto 等这类引擎中,
使得这些引擎可以查询 Hudi 表数据,从而具备 Hudi 所提供的 Snapshot Query 、Incremental Query 、Read Optimized Query 的能力。
Timeline
Hudi 内部对每个表维护了一个 Timeline ,由一组作用在表上的 Instant 对象组成。Instant 表示在某个时间点对表进行操作达到某一个状态的表示,包含3部分内容:
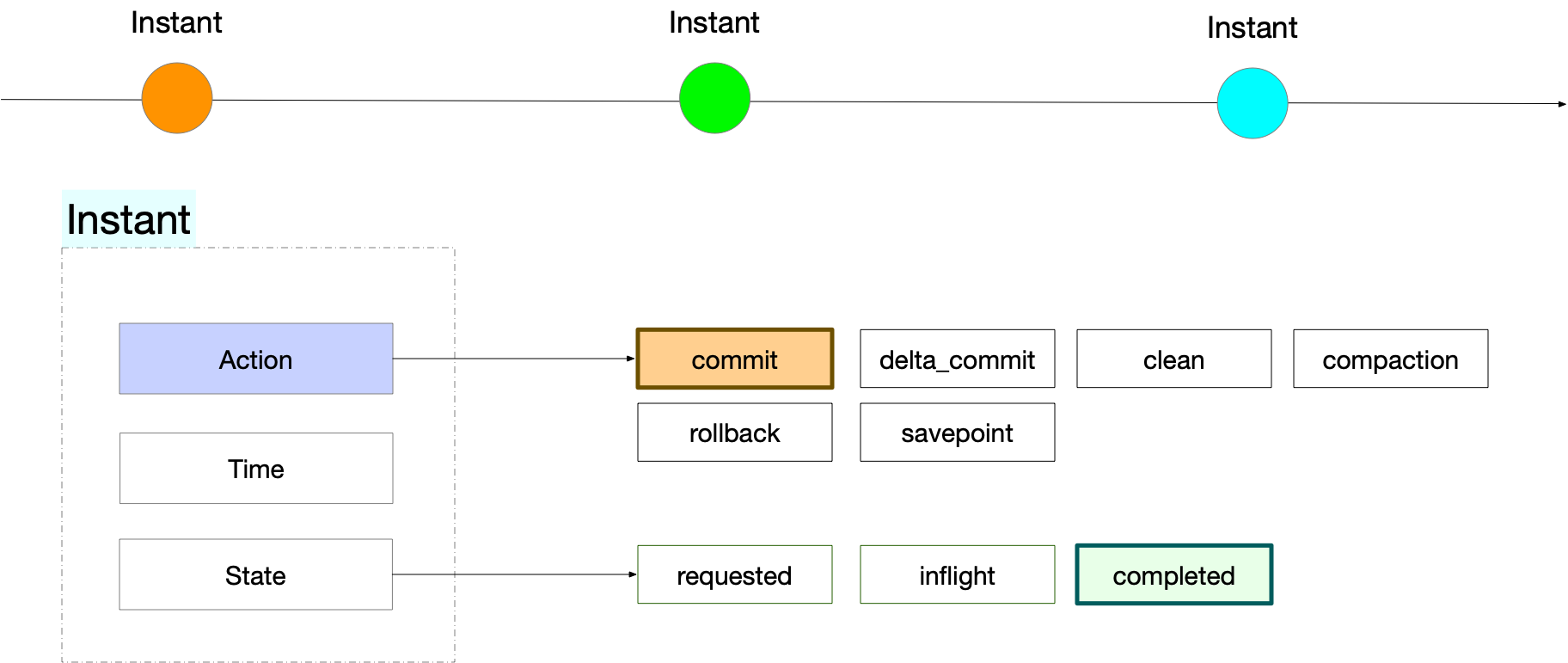
- Instant Action : 对 Hudi 表的执行操作类型
- COMMITS :将一批数据原子写入到表中
- CLEANS :后台清除表中不再需要的就版本文件
- DELTA_COMMIT :将一批数据原子写入到 Merge On Read 类型表中,其中部分或所有数据可能只写入到 delta 增量日志文件中
- COMPACTION :后台使用 Hudi 重组多种文件格式,例如:将更新操作的行式日志文件移动到列式,compaction 在 timeline 上表现为一种特殊的提交
- ROLLBACK :表示提交或增量提交未成功并回滚,删除写入期间生成的任何文件
- SAVEPOINT : 将某些文件组标记为”已保存”,cleaner 不会删除这些文件,也有助于恢复某一时间点上的数据表
- Instant Time : 表示一个时间戳,从 Instant Action 开始执行的时间顺序单调递增 ;
- Instant State :表示在指定的时间点(Instant Time)对 Hudi 表执行操作(Instant Action)后,表所处的状态
- REQUESTED :已调度但未初始化
- INFLIGHT :当前正在执行
- COMPLETED :操作执行完成

上图为官网给出的例子,展示了 Hudi 表上 10:00 至 12:00 之间发生的 upserts ,大约每5分钟一次 ,Hudi Timeline 会记录 COMMIT 元数据,以及在后台进行 CLEANING/COMPACTION 。
从数据生成到最终到达 Hudi 系统,可能存在延迟,如图中的 07:00、08:00、09:00 生成的数据,数据到达大约延迟了 3、2、1 小时,最终生成 COMIMIT 的时间才是 upsert 的时间。
对于数据到达时间(Arrival Time)和事件时间(Event Time)相关的数据延迟性(Latency)和完整性(Completeness)的权衡,Hudi 可以将数据 upsert 到更早时间的 buckets 或 folders 下。
通过使用 Timeline 管理,当增量查询 10:00 之后的最新数据时,可以高效的找到 10:00 之后发生过更新的文件,而不必根据延迟时间再去扫描更早时间的文件,比如这里,就不需要扫描 07:00、08:00、09:00 这些时刻对应的文件。
文件
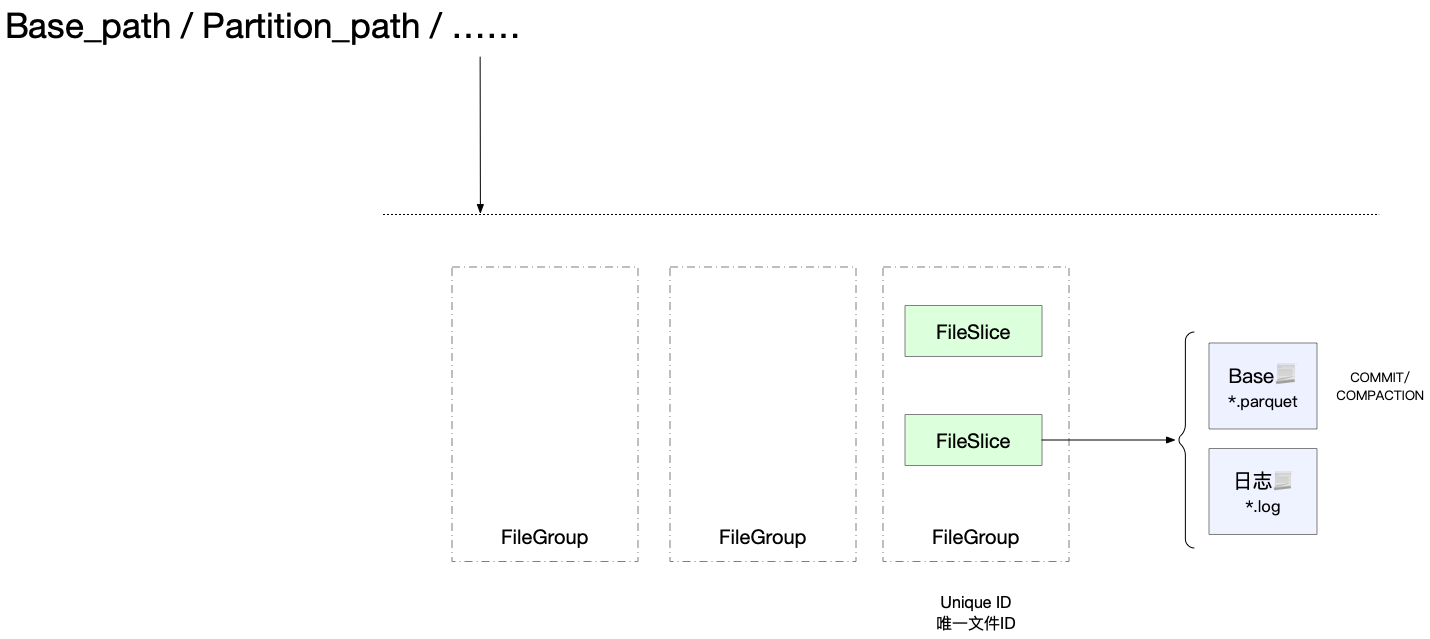
Hudi 采用 MVCC 设计,当执行 COMPACTION 操作时,会合并日志文件和 Base 文件,生成新的文件分片。
CLEAN 操作会清理掉不用的文件分片,释放存储空间。
索引
Hudi 会通过记录 key 与分区 path 组成 Hoodie Key ,即 Record Key + Partition Path , 通过将 Hoodie Key 映射到 file_group/file_id 。
一旦记录的第一个版本被写入文件中,对应的 Hoodie Key 就不会再改变了。
Hudi 提供多种索引来适配不同场景,需要根据具体的数据分布进行取舍,从而达到最佳的写入和查询效率。
场景一:日志去重
这种日志数据通常会有一个 create_time 时间戳,底表也是按照时间戳进行分区,最近几个小时或几天的数据需要频繁更新,更老的数据则不需要太多变化。
这种冷热分离的数据,推荐使用:
Bloom index
State index with TTL
Hash index
场景二:数据库导出(CDC)
更新的数据随机分布,没有规律可循,底表数据量通常比较大,新增数据量比较小。
Hash index
State index
HBase index
Hudi 表类型
Copy On Write
使用专门的列式文件格式存储数据,例如 parquet 格式,更新时保存多版本,并且在写的过程中通过异步的 Merge 来实现重写文件。Copy On Write 表只包含列式格式的 Base 文件,每次执行 COMMIT 操作会生成新版本的 Base 文件,最终执行 COMPACTION 操作时还是会生成列式格式的 Base 文件。所以,Copy On Write 表存在写放大的问题。
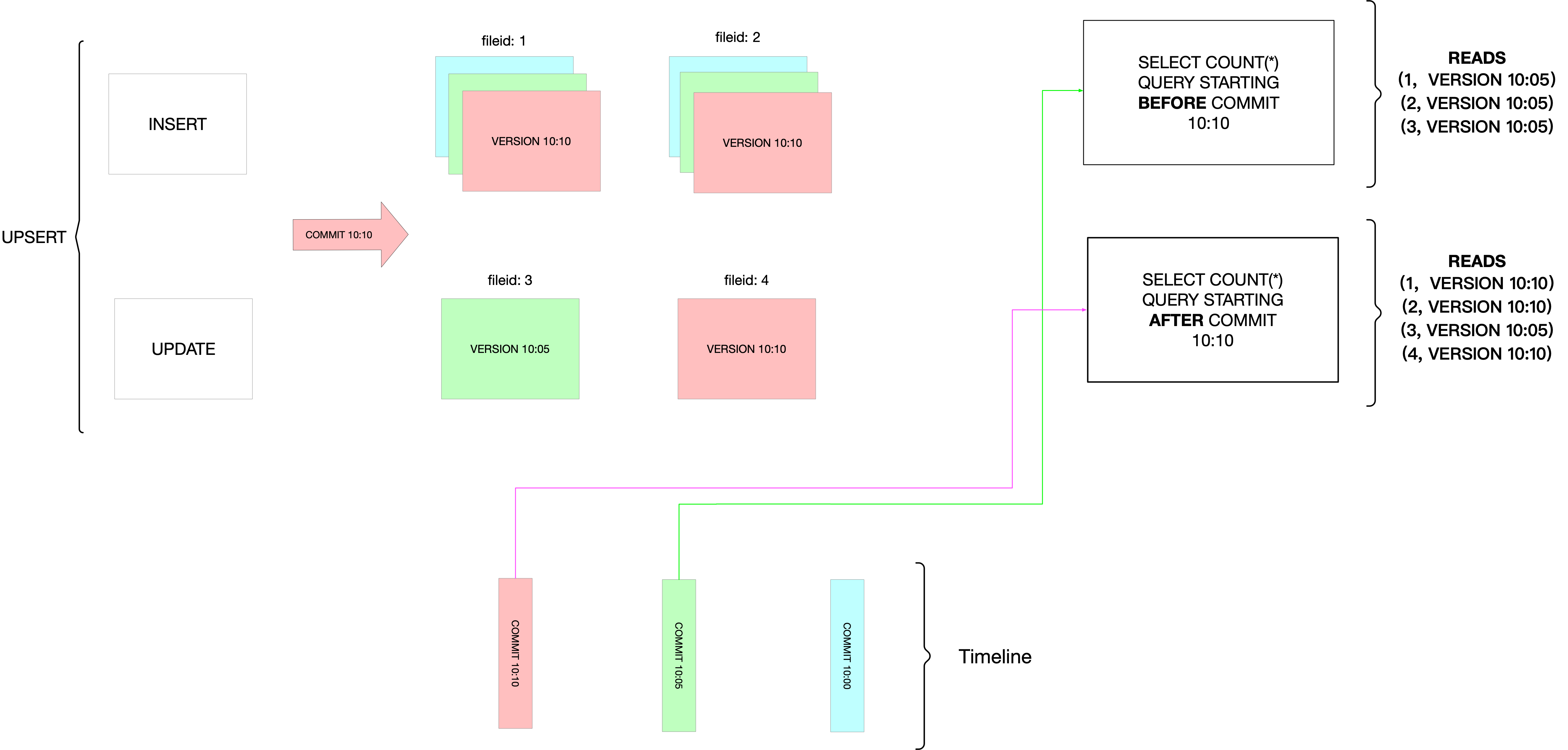
上图为官网给出的例子:
在写入数据时,对现有文件组的 UPDATE 操作会为该文件组生成一个新的文件分片,并标记提交时间。
INSERT 操作会分配一个新的文件组,并为该文件组写入其第一个文件分片。
写入的过程中也可以进行查询(例如:select count(*)),如果查询 COMMIT 为 10:10 之前的数据,
会首先检查最新提交的时间线,过滤出每个文件组中除了最新文件分片以外的所有文件分片,即把文件 ID 为 1、2、3 且版本为 10:05 的文件分片查询出来。
因此,查询不受任何写入失败/部分写入的影响,只查询已提交的数据。
Merge On Read
使用列式和行式混合存储,列式文件格式如 parquet ,行式文件格式如 avro ,所以 Merge On Read 表存在列式的 Base 文件,也存在行式的 Delta 文件。更新时写入到增量 Delta 文件中,之后通过同步或异步的 COMPACTION 操作,生成新版本的列式文件。
通常,需要有效的控制增量日志文件的大小,来平衡读放大和写方法的影响。
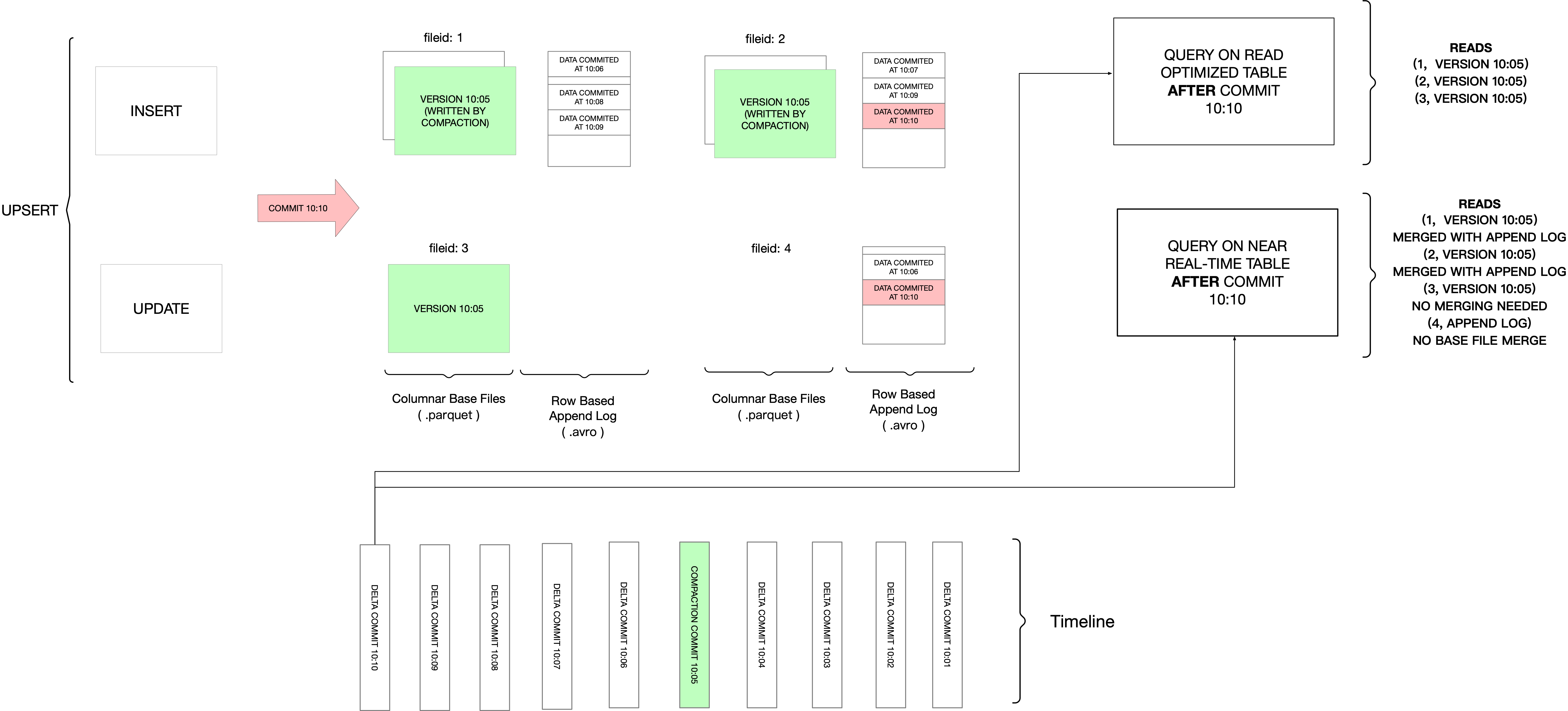
上图为官网给出的例子:
每个文件分组都对应一个增量日志文件(Delta Log File),COMPACTION 操作在后台定时执行,会把对应的增量日志文件合并到文件分组的 Base 文件中,生成新版本的 Base 文件。使用 Read Optimized Query 模式查询 10:10 之后的数据,只能查询到包含版本为 10:05 ,文件 ID 为 1、2、3 的文件;
使用 Snapshot Query 模式是可以查询到 10:05 之后的数据的。
Hudi Flink Writer
- 大致写入流程
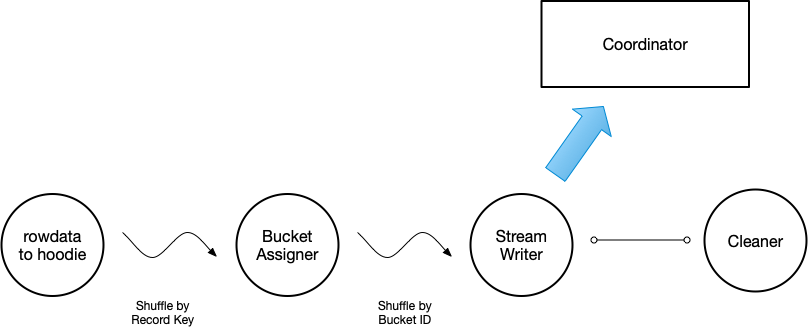
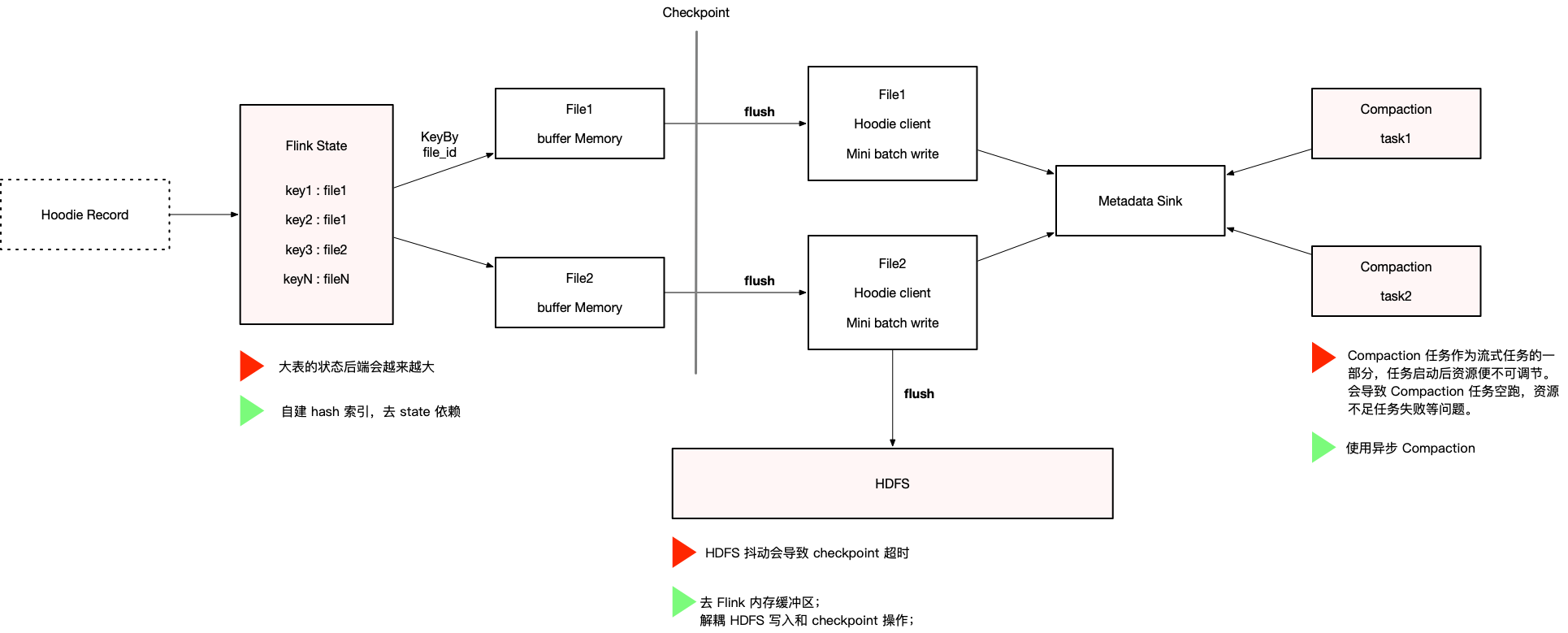
- Hudi_On_Flink写入问题及解决办法
- 写入状态机
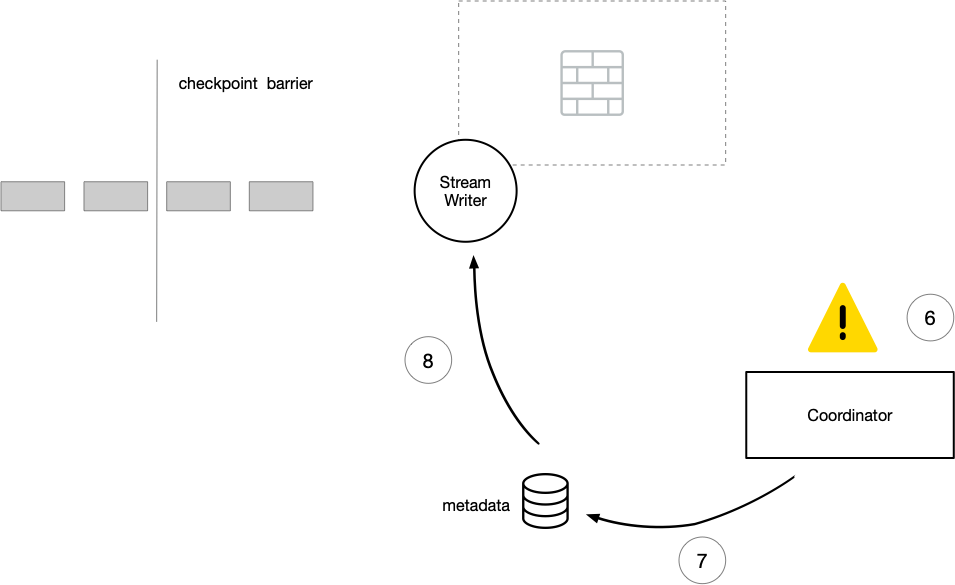
在作业刚启动时, Coordinator 会尝试去文件系统上新建表,如果当前表不存在,会在文件目录上写一些 meta 信息,进行表构建。
在收到所有 task 的初始化 meta 信息后, Coordinator 会开启一个新的 transaction 。
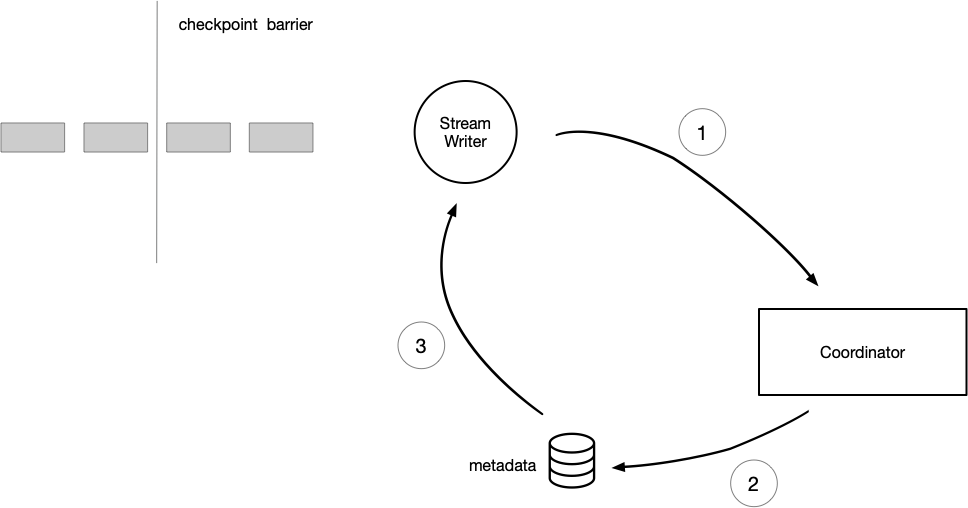
当 write task 看到了事务的发起之后,就会解锁当前数据的 flush 操作,writer 是会先在内存中积攒一批数据。
当达到内存阈值时,刷盘:
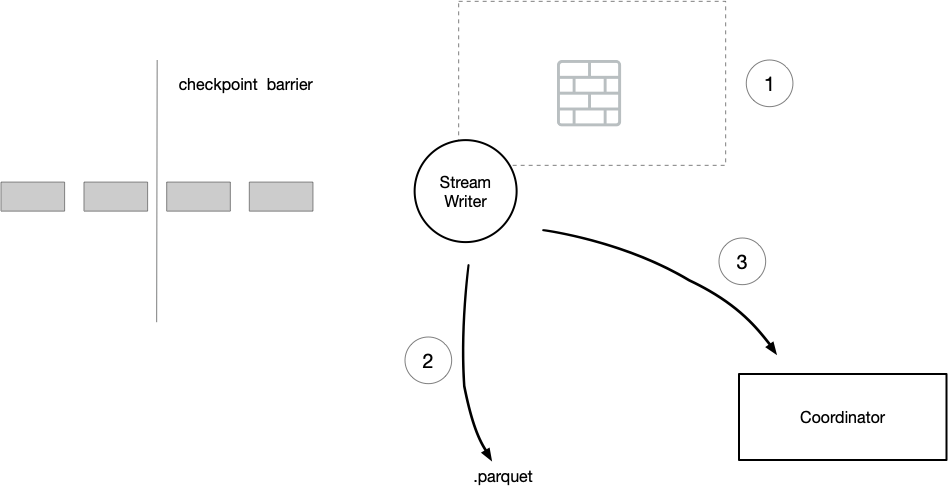
当上游的 checkpoint barrier 到达做快照时,刷盘:
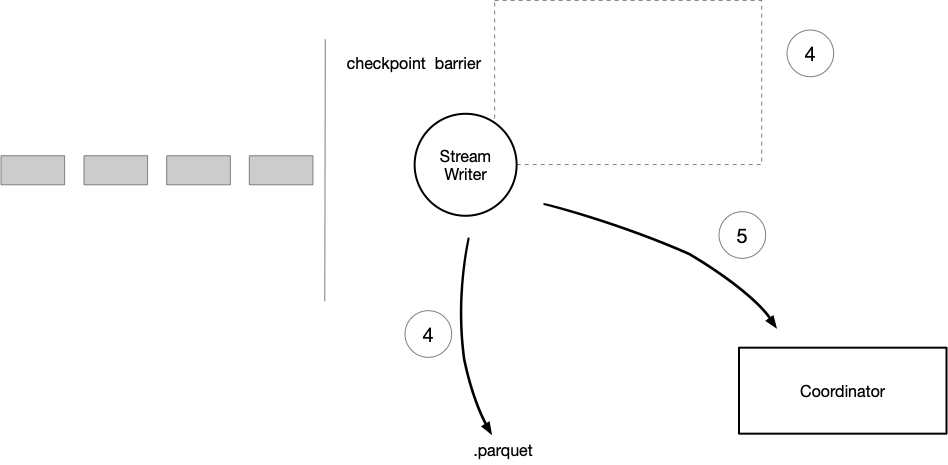
write task 在每次 flush 之后,都会发送 meta 信息给 Coordinator ,当 Coordinator 收到 checkpoint 的 success 事件之后,会提交对应的事务,并发起新一轮事务。
write task 看到新事务后,会解锁下一轮事务的写入。
遇到错误时,取消刷盘:
使用用例
创建 Hudi 表:
1 | CREATE TABLE h_table( |
更改 Hudi 表名:
1 | ALTER TABLE h0 rename to h0_1; |
插入 Hudi 表:
1 | INSERT INTO hudi_table |
Flink-CDC 整库同步:
1 | -- mysql catalog |
应用场景:
- CDC 数据库数据入仓库,使用 Flink-CDC connector 一次性导入或者消费 Kafka 中的 changelog
- 对接 Presto 等 OLAP 引擎,满足近实时分析场景
- 增量 ETL ,Hudi 支持存储流计算过程中的行级别变更,通过流读消费变更,可以实现端到端的近实时 ETL 生产
- 双流 join 应用场景
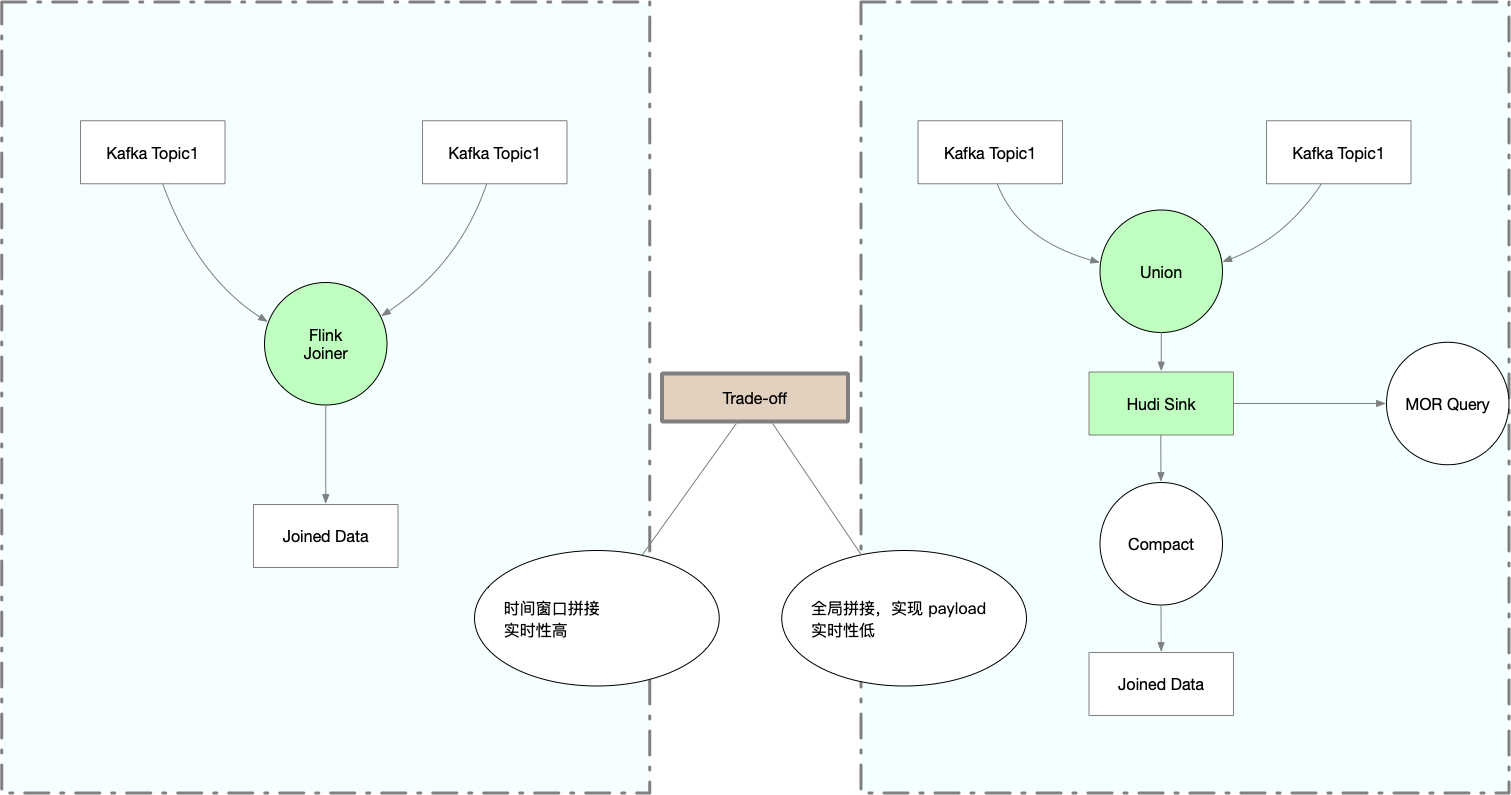
Roadmap:
- 流读语义增强
- Record Level Index
- 二级索引
- ID-based Schema Evolution
- Metastore Catalog
- 支持 Trino Connector
参考
Hudi 官网
Apache Hudi 架构设计和基本概念
FFA 2021