本文主要围绕 Flink 源码中 flink-streaming-java 模块。介绍如何使用 DataStream API 进行 Flink 流任务开发,flink-streaming-java 模块中的一些重要类,贯穿着介绍下从 DataStream
API 到 StreamGraph 的构建过程。
DataStream API使用一览
使用 DataStream API 通常有以下步骤:
- 如何创建 Environment(Local、Remote) 并设置属性
- setParallelism(int):StreamExecutionEnvironment
- setMaxParallelism(int):StreamExecutionEnvironment
- setBufferTimeout(long):StreamExecutionEnvironment
- enableCheckpointing(long,CheckpointingMode):StreamExecutionEnvironment
- setStateBackend(StateBackend):StreamExecutionEnvironment
- setStreamTimeCharacteristic(TimeCharacteristic):void
- 如何读取数据?添加 Source 数据源获得 DataStream
- fromElements(OUT …): DataStreamSource
… - readTextFile(String): DataStreamSource
… - readFile(FileInputFormat
,String): DataStreamSource … - socketTextStream(String ,int ,String ,long): DataStreamSource
… - createInput(InputFormat<OUT,?>,TypeInformation
): DataStreamSource … - addSource(SourceFunction
,TypeInformation ): DataStreamSource …
- 如何操作转换数据?
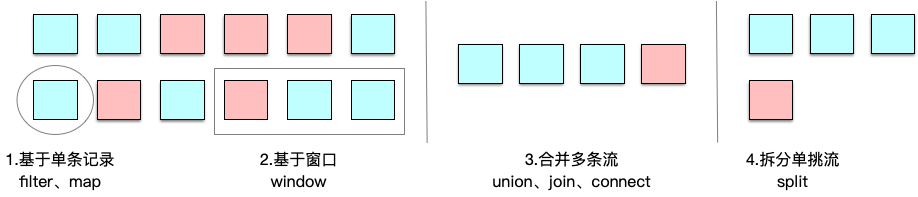
- Basic Transformations
map、filter、flatMap - KeyedStream Transformations
keyBy、aggregations、reduce - MultiStream Transformations
union、connect、coMap、coFlatMap、split、select
- Distribution Transformations
物理分组:
| 关系 | 表示 | 图示 |
|---|---|---|
| global | 全部发往第1个task | 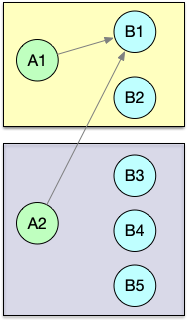 |
| broadcast | 广播,复制上游的数据发送到所有下游节点 | 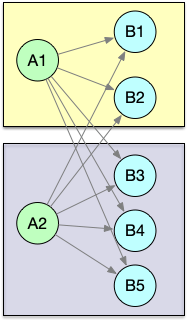 |
| forward | 上下游并发度一样时一对一发送 | 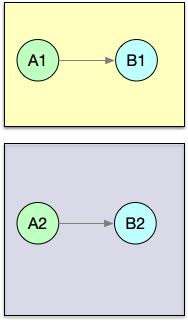 |
| shuffle | 随机均匀分配 | 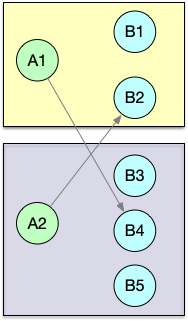 |
| reblance | Round-Robin(轮流分配) | 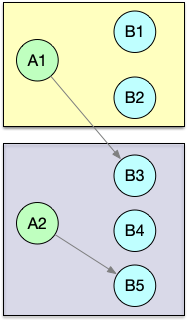 |
| rescale | Local Round-Robin (本地轮流分配), 只会看到本机的实例 |
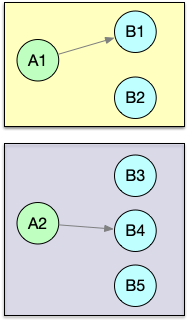 |
| partitionCustom | 自定义单播 |
- 如何输出数据?添加 Sink
- writeAsText(String path): DataStreamSink
… - writeAsCsv(String path): DataStreamSink
… - addSink(SinkFunction
sinkFunction): DataStreamSink
- 如何提交执行?
DataStream 通过不同的算子不停地在 DataStream 上实现转换过滤等逻辑,最终将结果输出到 DataSink 中。
在 StreamExecutionEnvironment 内部使用一个List<StreamTransformation<?>> transformations来保留生成 DataStream 的所有转换。
- execute():JobExecutionResult
我们看下基于 Flink DataStream API 的自带 WordCount 示例:实时统计单词数量,每来一个计算一次并输出一次。
1 | public class WordCount { |
源码剖析
StreamExecutionEnvironment
StreamExecutionEnvironment 是 Flink 流处理任务执行的上下文,是我们编写 Flink 程序的入口。根据执行环境的不同,选择不同的 StreamExecutionEnvironment 类,
有 LocalStreamEnvironment、RemoteStreamEnvironment 等。如下图: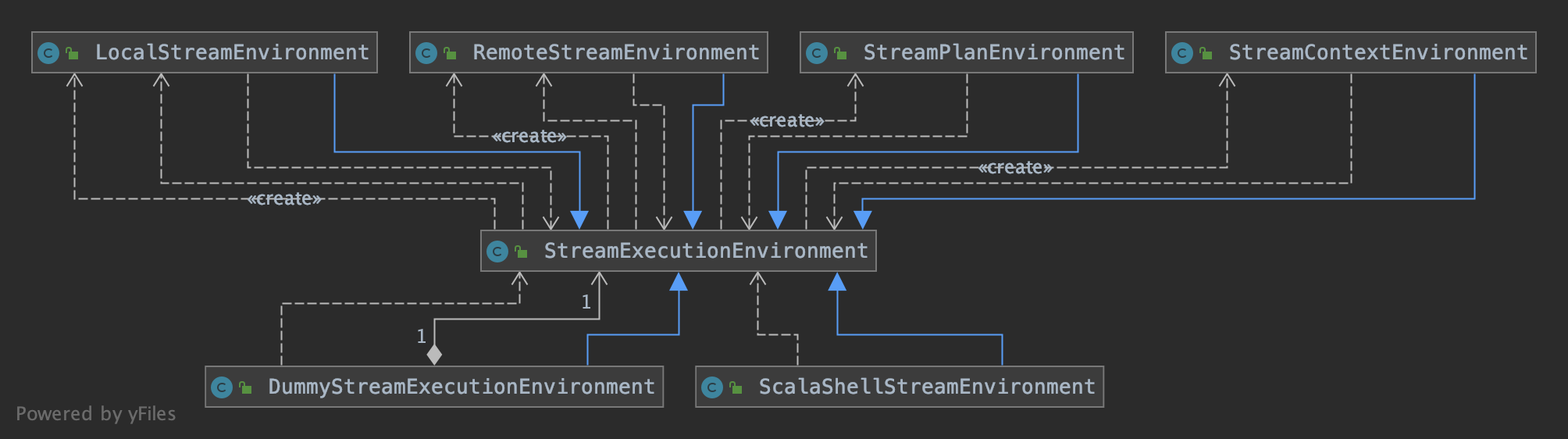
StreamExecutionEnvironment 依赖 ExecutionConfig 类来设置并行度等,依赖 CheckpointConfig 设置 Checkpointing 等相关属性。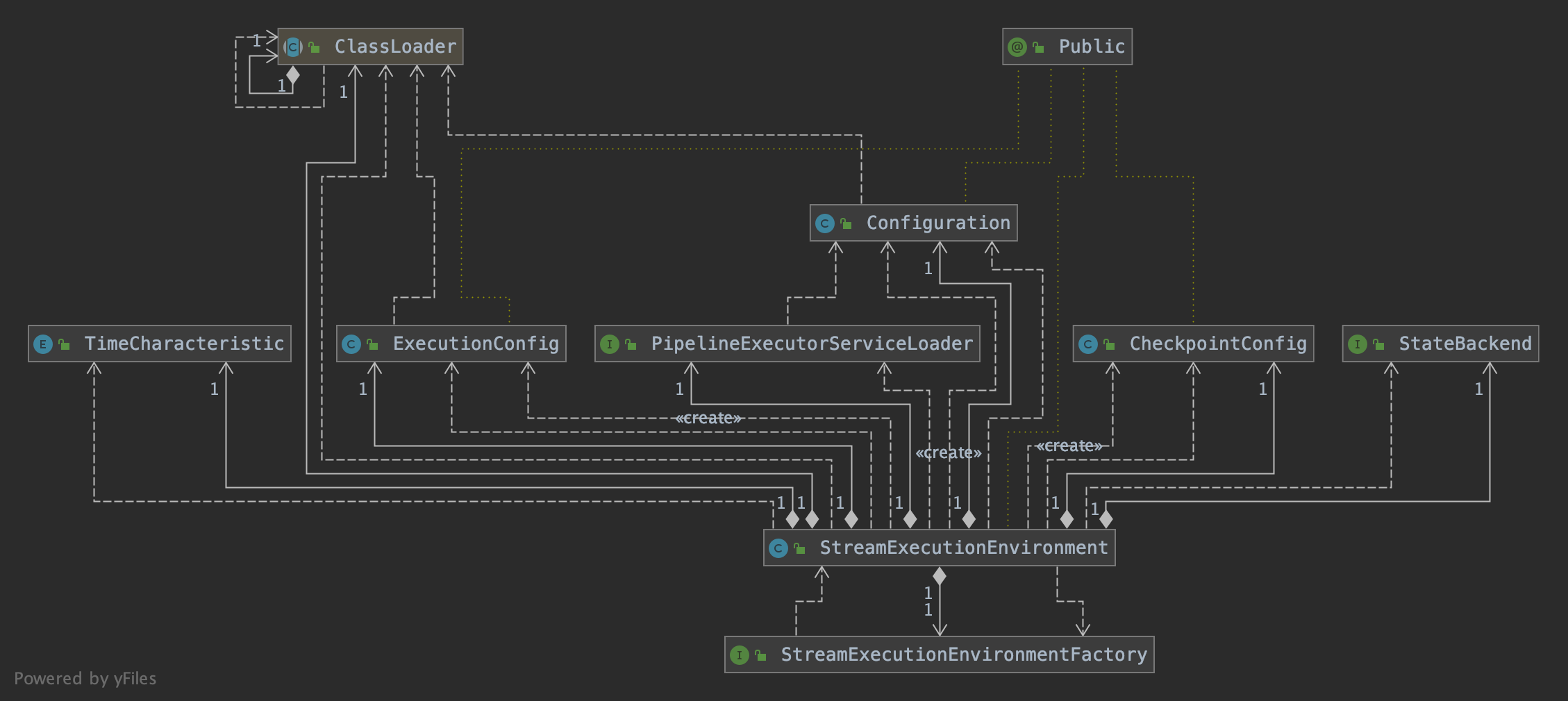
这里再补充说明下 StreamExecutionEnvironment类中的重要属性和方法:
Transformation
Transformation 代表了从一个或多个 DataStream 生成新 DataStream 的操作。在 DataStream 上通过 map 等算子不断进行转换,就得到了由 Transformation
构成的图。当需要执行的时候,底层的这个图就会被转换成 StreamGraph 。
Transformation 有很多子类,如 SourceTransformation、OneInputTransformation、TwoInputTransformation、SideOutputTransformation 等,分别对应了 DataStream 上的不同转换操作。
![]()
每一个 Transformation 都有一个关联 id,这个 id 是全局递增的,还有 uid、slotSharingGroup、parallelism 等信息。
![]()
查看 Transformation 的其中两个子类 OneInputTransformation、TwoInputTransformation 的实现,都对应有输入 Transformation,也正是基于此才能还原出 DAG 的拓扑结构。
Transformation 在运行时并不对应着一个物理转换操作,有一些操作只是逻辑层面上的,比如 split/select/partitioning 等。
Transformations 组成的 graph ,也就是我们写代码时的图结构如下:
1 | Source Source |
但是,在运行时将生成如下操作图,split/select/partitioning 等转换操作会被编码到边中,这个边连接 sources 和 map 操作:
1 | Source Source |
DataStream
一个 DataStream 就代表了同一种类型元素构成的数据流。通过对 DataStream 应用 map/filter 等操作,就可以将一个 DataStream 转换成另一个 DataStream 。
这个转换的过程就是根据不同的操作生成不同的 Transformation ,并将其加入到 StreamExecutionEnvironment 的 transformations 列表中。
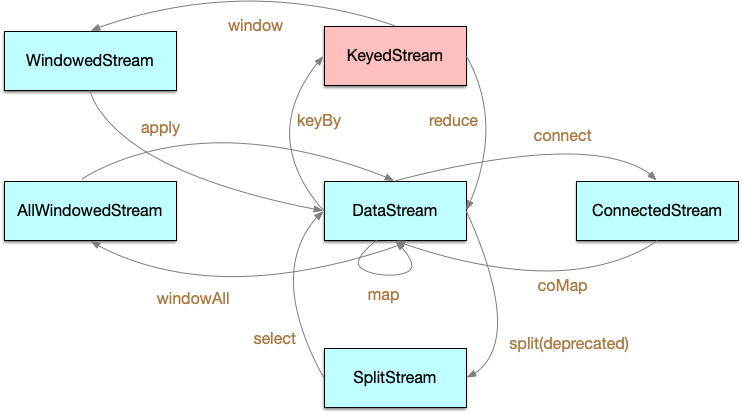
DataStream 的子类包括 DataStreamSource、KeyedStream、IterativeStream、SingleOutputStreamOperator。
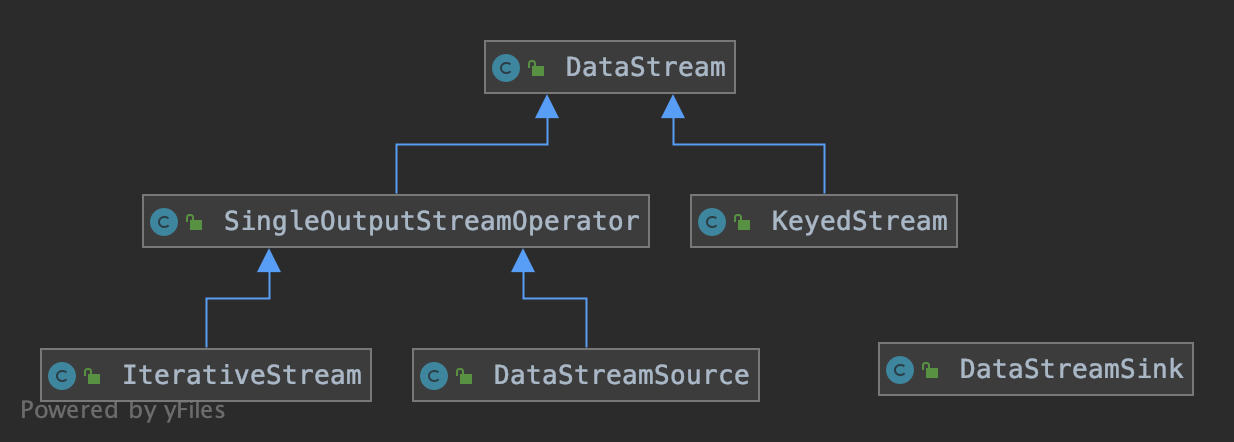
除了 DataStream 及其子类以外,其它的表征数据流的类还有 ConnectedStreams、WindowedStream、AllWindowedStream,这些会在后续的文章中陆续介绍。
DataStream 类中的重要属性和方法:
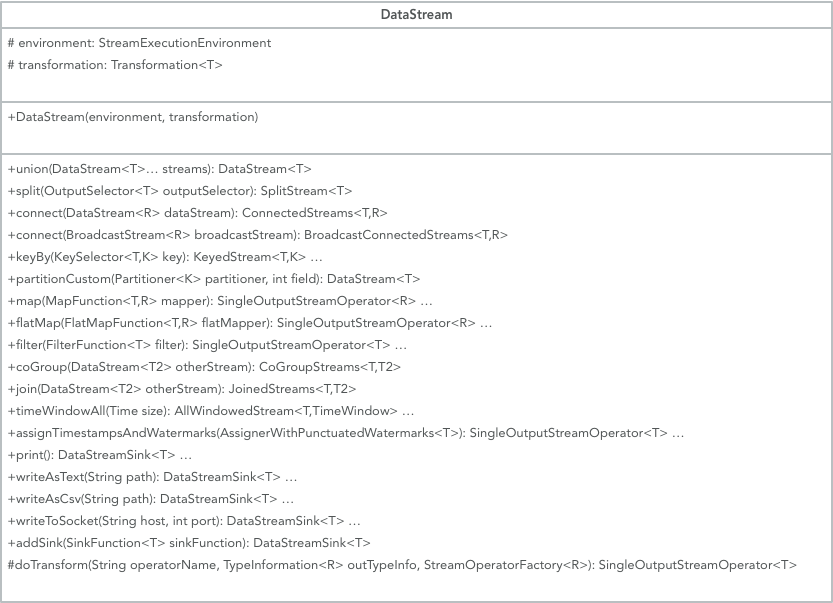
下面我们看下 map 操作是如何被添加进来的:
1 | public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) { |
1 |
|
接着我们看下其中一个比较重要的方法 doTransform :
1 | protected <R> SingleOutputStreamOperator<R> doTransform( |
StreamOperator
在操作 DataStream 的时候,比如 DataStream.map(MapFunction<T, R> mapper) 时,都会传入一个自定义的 Function 。那么这些信息是如何保存在 Transformation 中的呢?
这里就引入了一个新的接口 StreamOpertor ,DataStream 上的每一个 Transformation 都对应了一个 StreamOperator,StreamOperator 是运行时的具体实现,会决定 UDF 的调用方式。
StreamOperator 的类继承关系如下:
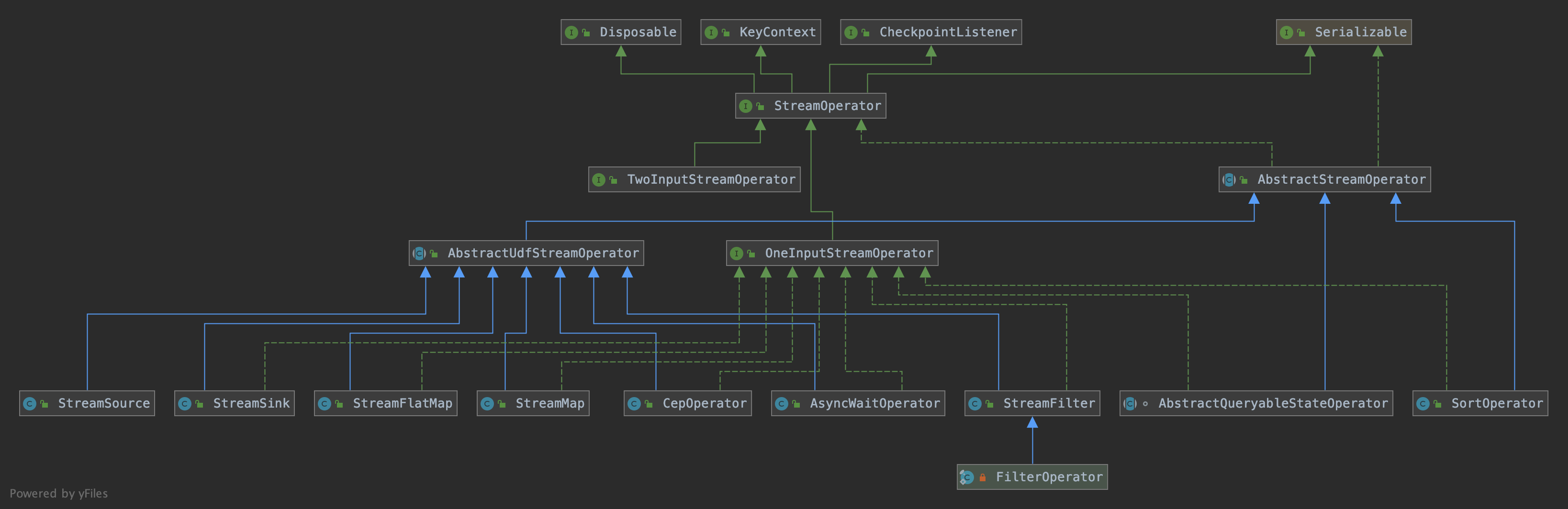
接口 StreamOpertor 定义了对一个具体的算子的生命周期的管理。StreamOperator 的两个子接口 OneInputStreamOperator 和 TwoInputStreamOperator 提供了数据流中具体元素的操作方法,而 AbstractUdfStreamOperator 抽象子类则提供了自定义处理函数对应的算子的基本实现:
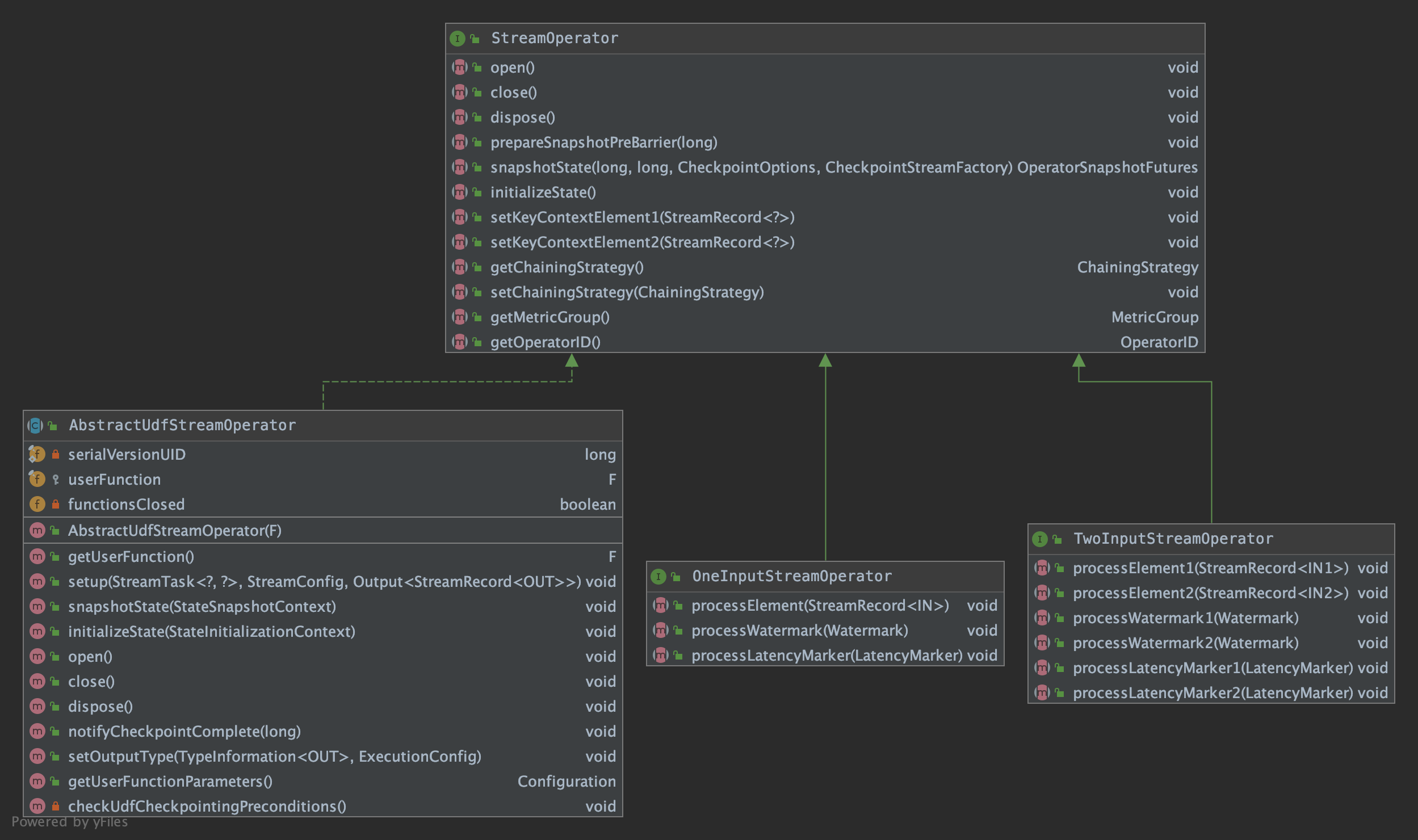
下面我们还是拿 map 举例,map 操作对应的 StreamOperator 为 StreamMap ,继承了 AbstractUdfStreamOperator 类,实现了 OneInputStreamOperator 接口:
1 |
|
以上,我们可以知道通过 DataStream -> Function -> StreamOperator -> StreamTransformation 这种依赖关系,就可以完成 DataStream 的转换,并且可以保存数据流和应用在流上
的算子之间的关系。
Function

StreamGraph
StreamGraph 是在 Client 端构造的。
了解 StreamGraph 之前我们首先要知道 StreamGraphGenerator 这个类,它会基于 StreamExecutionEnvironment 的 transformations 列表来生成 StreamGraph。
首先看下 StreamGraphGenerator 的 generate() 方法,这个方法会由触发程序执行的方法 StreamExecutionEnvironment.execute() 调用到:
1 | public StreamGraph generate() { |
在遍历 List
转换为 StreamGraph 中的 StreamNode 节点,并会为上下游节点添加边 StreamEdge。下面看下 transform() 方法:
1 | private Collection<Integer> transform(Transformation<?> transform) { |
对于另外一部分 Transformation ,如 partitioning, split/select, union,并不包含真正的物理转换操作,是不会生成 StreamNode 的,而是生成一个带有特定属性的虚拟节点。
当添加一条有虚拟节点指向下游节点的边时,会找到虚拟节点上游的物理节点,在两个物理节点之间添加边,并把虚拟转换操作的属性附着上去。下面我们首先看下 transformOneInputTransform() 方法:
1 | private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) { |
接着看下 StreamGraph 中对应的添加节点的方法:
1 | public <IN, OUT> void addOperator( |
下面我们再看下 transformPartition() 非物理节点的转换方法:
1 | private <T> Collection<Integer> transformPartition(PartitionTransformation<T> partition) { |
在实际的物理节点执行添加边的操作时,会判断上游是不是虚拟节点,如果是则会一直递归调用,将虚拟节点的信息添加到边中,直到连接到一个物理转换节点为止:
1 | private void addEdgeInternal(Integer upStreamVertexID, |
StreamGraph 是 Flink 任务最接近用户逻辑的 DAG 表示,后面到具体执行时还会进行一系列转换。
类之间的层级关系
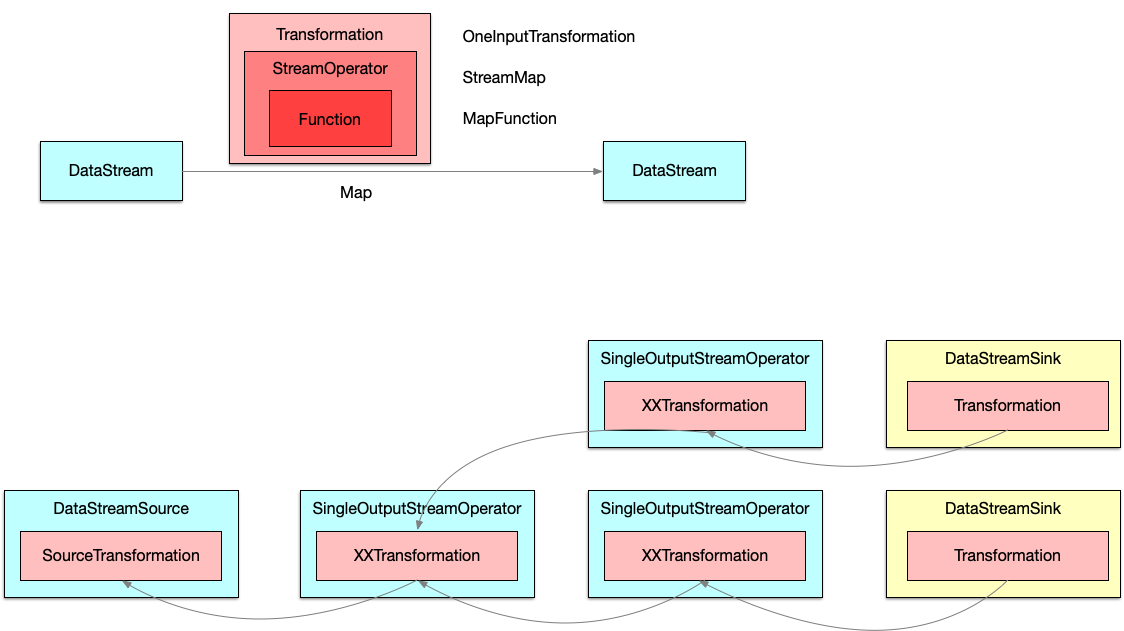
map 转换将用户自定义函数 MapFunction 包装到 StreamMap 这个 StreamOperator 中,再将 StreamMap 包装到 OneInputTransformation,最后该 transformation 会存到
StreamExecutionEnvironment 中。当调用 env.execute() 时,会遍历其中的 transformations 集合构造出 StreamGraph 。