本文主要围绕 Flink 源码中 flink-streaming-java 模块。介绍下 StreamGraph 转成 JobGraph 的过程等。
StreamGraph 和 JobGraph 都是在 Client 端生成的,也就是说我们可以在 IDE 中通过断点调试观察 StreamGraph 和 JobGraph 的生成过程。
前置调用
从 StreamExecutionEnvironment 中的 execute() 方法一直往下跟:
1 | /** |
下面我们详细看看 StreamExecutionEnvironment 中的 executeAsync 方法:
1 | /** |
executeAsync 有涉及到 PipelineExecutorFactory 和 PipelineExecutor 。
PipelineExecutorFactory 是通过 SPI ServiceLoader 加载的,我们看下 flink-clients 模块的 META-INF.services 文件:
PipelineExecutorFactory 的实现子类,分别对应着 Flink 的不同部署模式,local、standalone、yarn、kubernets 等:
这里我们只看下 LocalExecutorFactory 的实现:
1 |
|
PipelineExecutor 的实现子类与 PipelineExecutorFactory 与工厂类一一对应,负责将 StreamGraph 转成 JobGraph,并生成 ClusterClient 执行任务的提交: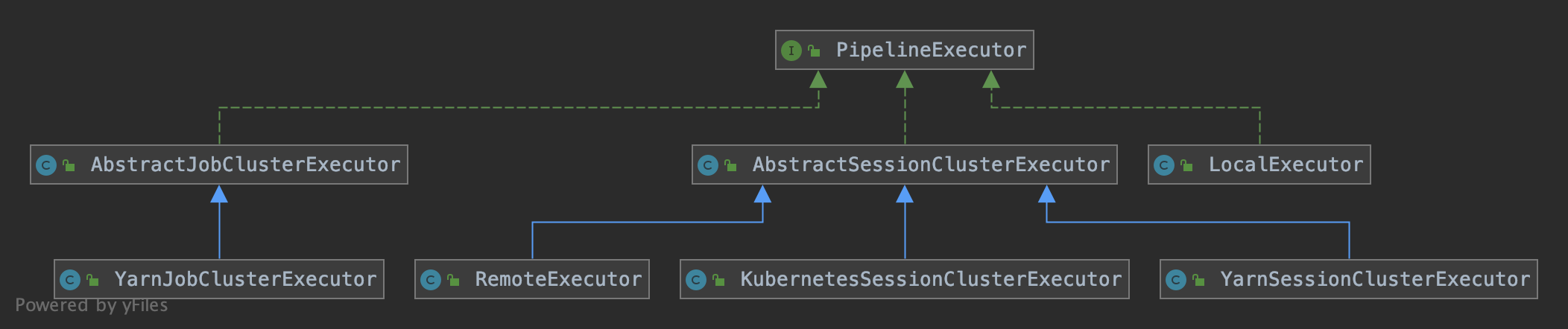
LocalExecutorFactory 对应的 LocalExecutor 实现如下:
1 |
|
回归主题,我们看下 FlinkPipelineTranslationUtil 的 getJobGraph() 方法:
1 | public static JobGraph getJobGraph( |
接着走到 StreamGraphTranslator 的 translateToJobGraph 方法:
1 | public class StreamGraphTranslator implements FlinkPipelineTranslator { |
StreamGraph 到 JobGraph 的转换
接着走到 StreamGraph 中的 getJobGraph() 方法:
1 | public JobGraph getJobGraph(@Nullable JobID jobID) { |
接着走到 StreamingJobGraphGenerator 的 createJobGraph() 方法:
1 | /** |