Flink CDC 2.0 的设计方案,借鉴了 Netflix 的 DBLog paper 实现全程无锁,并基于 Flink FLIP-27 Source 实现水平扩展,并支持全量阶段 checkpoint 。
1.x 集成 Debezium
Flink CDC 1.x 是通过集成 Debezium 引擎来采集数据,支持全量 + 增量的模式,保证所有数据的一致性。存在以下痛点:
- 一致性通过加锁保证
Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库 hang 住,表级锁会锁住表读 - 不支持水平扩展
Debezium 为单机节点,在全量读取阶段,如果表非常大,读取时长可能达到小时级 - 全量读取阶段不支持 checkpoint
CDC 读取分为两个阶段,全量和增量,全量读取阶段不支持 checkpoint,fail 之后则需要重新读取。
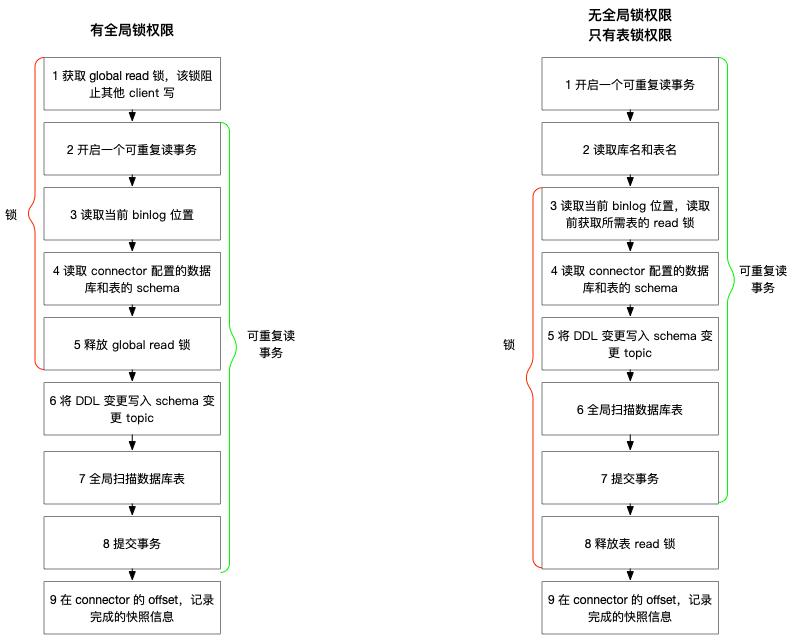
全局锁
首先是获取一个锁,然后去开启可重复读事务。锁住操作是读取 binlog 的起始位置和当前表的 schema 。这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 可以对应上,因为表的 schema 是会变的,比如增加列或删除列。在读取这两个信息后, SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成之后,会启动 BinlogReader 从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。表锁
表锁是全局锁的退化版,因为全局锁的权限比较高,在某些场景下用户只能得到表锁。表锁锁的时间会更长,表锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完之后才能释放。
FLUSH TABLES WITH READ LOCK
- 该命令等待所有正在进行的 update 完成,同时阻止所有新来的 update
- 该命令执行成功前必须等到所有正在运行的 select 完成,更换的情况是,在等待正在运行 select 完成时,DB 实际上处于不可用状态,即使是新加入的 select 也会被阻止,这是 MySQL Query Cache 机制
- 该命令阻止其他事务 commit
单 Chunk 读一致性
与 DBLog 不同,Flink CDC 2.0 没有维护额外的表,而是在 select 数据前后使用 SHOW MASTER STATUS 获取 binlog offset ,这种方式避免了侵入源端系统。
快照读取逻辑: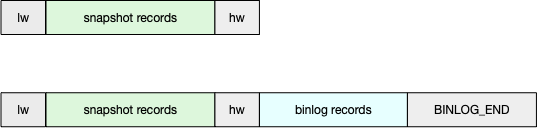
SHOW MASTER STATUS获取 lw,插入队列- 读取该分片内的记录,插入记录
SHOW MASTER STATUS获取 hw,插入队列- 判断 lw 和 hw 之间是否有增量变更
- 如果没有变更,队列中插入 BINLOG_END 记录
- 否则读取 [lw,hw] 之间的 binlog 并插入队列,最后一条记录为 BINLOG_END
修正队列里的数据,获取该分片 point-in-time 为 hw 的数据: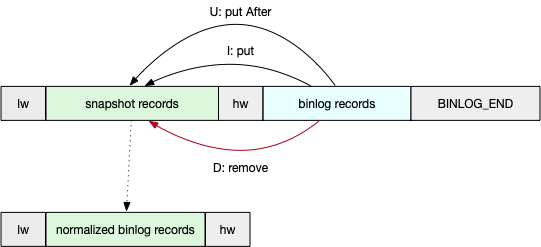
- 将 lw 加入到 normalizedBinlogRecords
- 遍历 binlogRecords 中的记录
- 对于删除记录,将其从 snapshotRecords 删除
- 对于更新记录,将记录中的 After 作为 READ 记录 map.put 到 snapshotRecords
- 对于创建记录,使用 map.put 到 snapshotRecords
- 将 snapshotRecords.values 加入到 normalizedBinlogRecords
- 将 hw 加入到 normalizedBinlogRecords
增量阶段
单 Chunk 读取是在多个 SourceReader 上并发执行,互不影响。假设一个任务同步的三张表 t1/t2/t3 被切分成 6 个分片,由于并发执行,其高低水位在 binlog 上的位置可能如下:
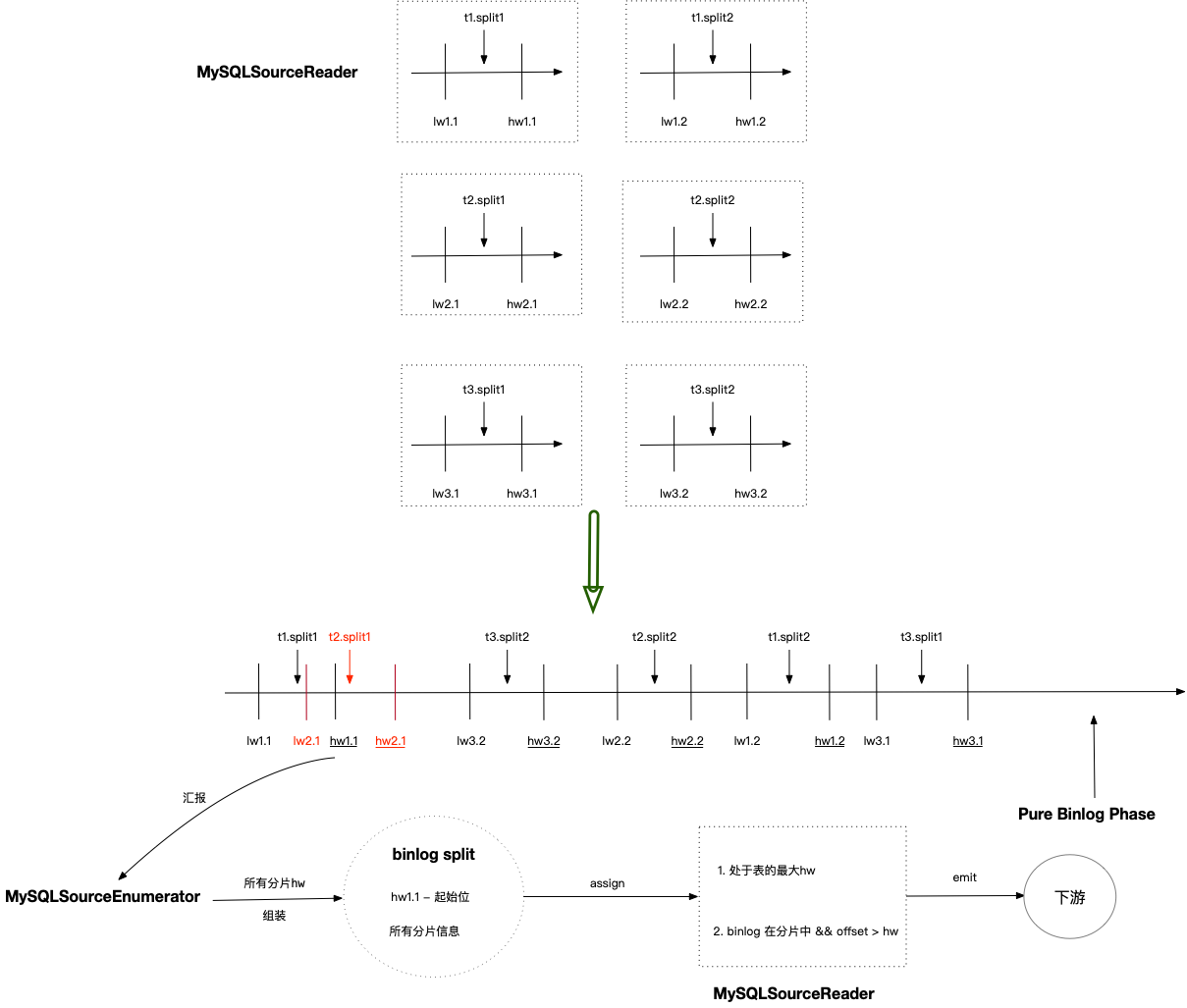
可以看出,t1.split1 和 t2.split1 读取的 binlog 范围有交叉,都读取了 [lw2.1,hw1.1] 之间的 binlog,t3.split2 可以早于 t3.split1 执行。这些交叉或者乱序并不影响正确性,因为全量阶段 MysqlSourceReader 会将每个 split 的 hw 汇报给 MysqlSourceEnumerator ,在增量阶段通过这些 hw 信息来保证 binlog 处理不丢失。
当 MysqlSourceEnumerator 把所有 split 的 hw 收集齐之后,会创建一个 binlog split , 该分片包含了需要读取 binlog 的起始位置(所有分片 hw 的最小值)和所有分片的 hw 信息。MysqlSourceEnumerator 把该 binlog 分片 assign 给一个 MysqlSourceReader ,任务从全量阶段转为增量阶段。
MysqlSourceReader 在读取 binlog 数据之后,通过以下条件判断记录是否应该发送给下游:
- 判断当前记录已经处于所在表的最大 hw ,即该表已经进入 Pure Binlog Phase ,对于这样的 binlog 记录,不需要进行比较,直接发送给下游
- 当一个 binlog 记录属于一个分片的主键范围时,如果该记录在这个分片的 hw 之后,则该记录应该发送给下游
具体代码实现
MySql cdc 类图关系如下:

MySqlSourceReader
1 | public class MySqlSourceReader<T> |
SourceReaderBase:
1 | public abstract class SourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT> implements SourceReader<T, SplitT> { |
MySqlSourceReaderTest
1 | public class MySqlSourceReaderTest extends MySqlSourceTestBase { |
测试类中执行的 sql 脚本如下:
1 | CREATE TABLE customers ( |
下面来监测一下数据变化:
创建的 MySqlBinlogSplit 格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42{
"splitId":"binlog-split",
"binlogSplit":true,
"completedSplit":true, // totalFinishedSplitSize == finishedSnapshotSplitInfos
"finishedSnapshotSplitInfos":[
],
"snapshotSplit":false,
"startingOffset":{
"filename":"mysql-bin.000003",
"gtidSet":"fb8daa95-9602-11ec-9adb-0242ac110003:1-35",
"offset":{
"ts_sec":"0",
"file":"mysql-bin.000003",
"pos":"11790",
"gtids":"fb8daa95-9602-11ec-9adb-0242ac110003:1-35",
"row":"0",
"event":"0"
},
"position":11790,
"restartSkipEvents":0,
"restartSkipRows":0,
"serverId":0,
"timestamp":0
},
"endingOffset":{
"filename":"",
"offset":{
"ts_sec":"0",
"file":"",
"pos":"-9223372036854775808",
"row":"0",
"event":"0"
},
"position":-9223372036854775808,
"restartSkipEvents":0,
"restartSkipRows":0,
"serverId":0,
"timestamp":0
},
"totalFinishedSplitSize":0
}读取的 SourceRecord 格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28SourceRecord{
sourcePartition={server=mysql_binlog_source},
sourceOffset={transaction_id=null, ts_sec=1645771455, file=mysql-bin.000003, pos=11855, gtids=a5adbd99-9603-11ec-a0a1-0242ac110003:1-35, row=1, server_id=223344, event=2}
}
ConnectRecord{
topic='mysql_binlog_source.customer_va47fu.customers',
kafkaPartition=null,
key=Struct{id=103},
keySchema=Schema{mysql_binlog_source.customer_va47fu.customers.Key:STRUCT},
value=Struct{
before=Struct{id=103,name=user_3,address=Shanghai,phone_number=123567891234},
after=Struct{id=103,name=user_3,address=Hangzhou,phone_number=123567891234},
source=Struct{
version=1.5.4.Final,
connector=mysql,
name=mysql_binlog_source,
ts_ms=1645771455000,
db=customer_va47fu,
table=customers,
server_id=223344,
gtid=a5adbd99-9603-11ec-a0a1-0242ac110003:36,
file=mysql-bin.000003,pos=11995,
row=0
},
op=u,
ts_ms=1645771666855
},
valueSchema=Schema{mysql_binlog_source.customer_va47fu.customers.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}读取一个事件数据之后,MySqlBinlogSplit 数据变化如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42{
"binlogSplit":true,
"completedSplit":true,
"startingOffset":{
"filename":"mysql-bin.000003",
"gtidSet":"a5adbd99-9603-11ec-a0a1-0242ac110003:1-35",
"offset":{
"ts_sec":"1645771455",
"file":"mysql-bin.000003",
"pos":"11855", // 起始位置由原来的 11790 变成了 11855
"gtids":"a5adbd99-9603-11ec-a0a1-0242ac110003:1-35",
"row":"1",
"server_id":"223344",
"event":"2"
},
"position":11855,
"restartSkipEvents":2,
"restartSkipRows":1,
"serverId":223344,
"timestamp":1645771455
},
"endingOffset":{
"filename":"",
"offset":{
"ts_sec":"0",
"file":"",
"pos":"-9223372036854775808",
"row":"0",
"event":"0"
},
"position":-9223372036854775808,
"restartSkipEvents":0,
"restartSkipRows":0,
"serverId":0,
"timestamp":0
},
"finishedSnapshotSplitInfos":[
],
"snapshotSplit":false,
"totalFinishedSplitSize":0
}
MysqlSplitReader
1 | public class MySqlSplitReader implements SplitReader<SourceRecord, MySqlSplit> { |
BinlogSplitReaderTest
先 SnapshotSplitReader ,再 BinlogSplitReader
1 | public class BinlogSplitReaderTest extends MySqlSourceTestBase { |
测试类中执行的 sql 脚本如下:
1 | -- create table whose split key is evenly distributed |
参考资料
Percona文章- FLUSH TABLES WITH READ LOCK 命令行影响
Flink CDC 2.0实现原理剖析