本文将基于 flink release-1.11 源码,简单分析下 TopN function 的实现。
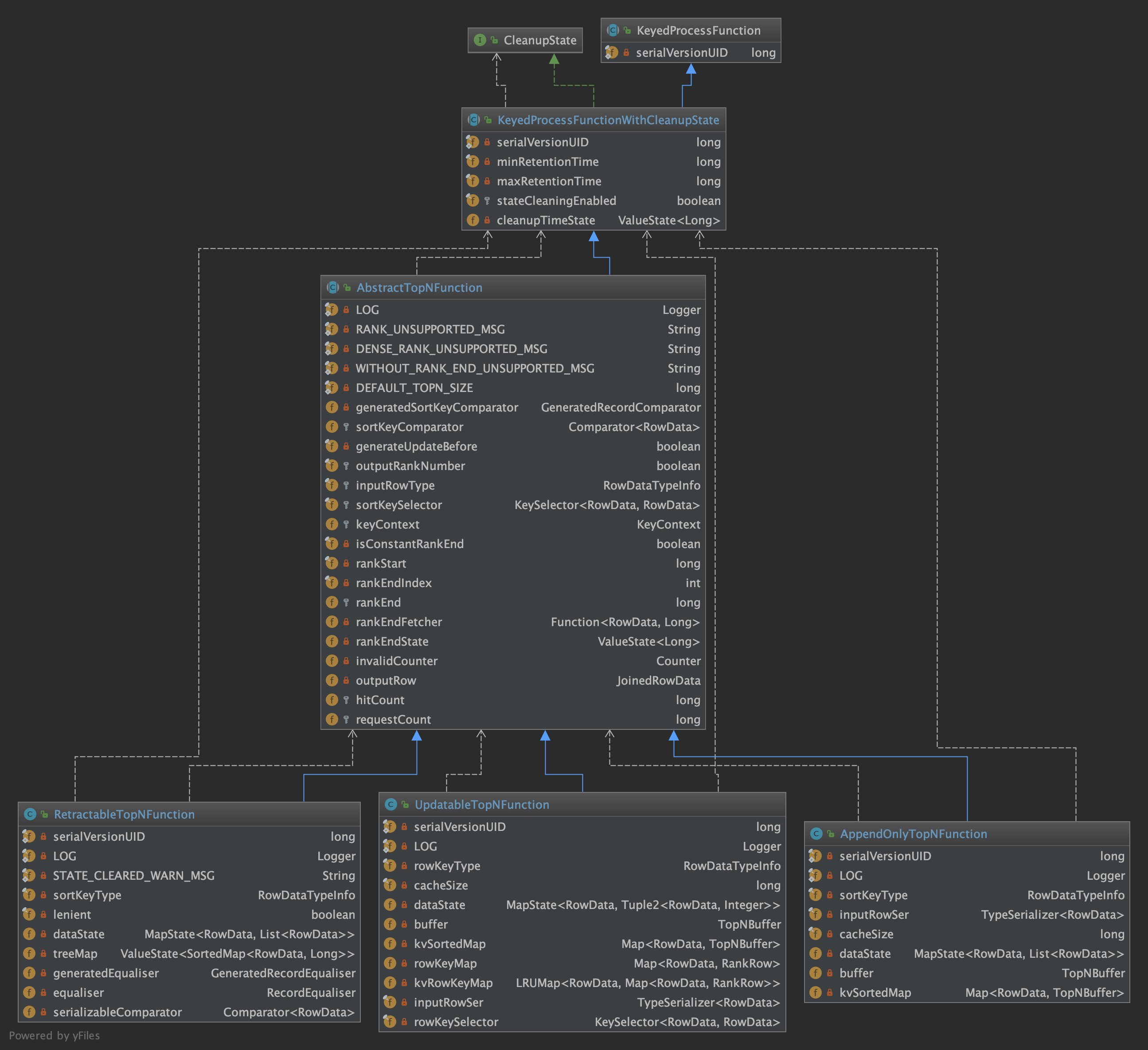
AbstractTopNFunction
AbstractTopNFunction 中有如下属性,定义 sortKey selector 和 comparator,rankEnd 相关参数:
1 |
|
AbstractTopNFunction 的 open() 方法主要从状态后端获取 rankEndState,并初始化类属性:
1 |
|
AbstractTopNFunction 的 initRankEnd() 方法根据 input row 来动态获取 rankEnd :
1 |
|
AbstractTopNFunction 的 checkSortKeyInBufferRange() 方法来判断 input row 是否应该被放到其 key 对应的 TopBuffer 中:
- 将 input row 与 TopBuffer 中的最后一个 entry 比较,comparator 返回 true 则将 input row 丢到 TopBuffer 中;
- comparator 返回 false,当前 TopBuffer 中的 entry 个数还没有达到默认的 TopN size,也将 input row 丢到 TopBuffer 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* Checks whether the record should be put into the buffer.
*
* @param sortKey sortKey to test
* @param buffer buffer to add
* @return true if the record should be put into the buffer.
*/
protected boolean checkSortKeyInBufferRange(RowData sortKey, TopNBuffer buffer) {
Comparator<RowData> comparator = buffer.getSortKeyComparator();
Map.Entry<RowData, Collection<RowData>> worstEntry = buffer.lastEntry();
if (worstEntry == null) {
// return true if the buffer is empty. TopNBuffer 是空的,直接返回 true
return true;
} else {
RowData worstKey = worstEntry.getKey();
//执行 TopN 比较器
int compare = comparator.compare(sortKey, worstKey);
if (compare < 0) {
// 如果满足条件,可以放到 TopNBuffer 中
return true;
} else {
// 到达的数据条数还没有达到默认的 TopN 大小 100,也可以放到 TopNBuffer 中
return buffer.getCurrentTopNum() < getDefaultTopNSize();
}
}
}
AbstractTopNFunction 的 createOutputRow() 方法用于构建 output row,区分带不带 rank 序号:
1 | /** |
AppendOnlyTopNFunction
AppendOnlyTopNFunction 中有如下属性,状态后端 MapState 和本地堆内存 TopNBuffer 结合使用:
1 | /** |
AppendOnlyTopNFunction 的 open() 方法中从状态后端中获取当前 key 的 TopN list:
1 | public void open(Configuration parameters) throws Exception { |
AppendOnlyTopNFunction 的 processElement() 方法处理数据,判断当前 input row 是否可以丢到 TopNBuffer 中:
1 |
|
AppendOnlyTopNFunction 的 initHeapStates() 是在处理 input row 之前,在堆内存中初始化 TopNBuffer,并将状态后端存储的 TopN list 设置到 TopNBuffer 中:
1 | private void initHeapStates() throws Exception { |
AppendOnlyTopNFunction 的 processElementWithoutRowNumber() 方法是处理丢到 TopNBuffer 中的 input row,决定这条数据是否被 Delete :
1 | private void processElementWithoutRowNumber(RowData input, Collector<RowData> out) throws Exception { |
AppendOnlyTopNFunctionTest
1 | /** |
1 | abstract class TopNFunctionTestBase { |
1 | abstract class TopNFunctionTestBase { |
输出结果为:
1 | Output element -> +I(book,2,12) |
RetractableTopNFunction
内部使用 TreeMap 进行 TopN 排序,可以对数据执行撤回操作,RowKind.UPDATE_BEFORE(-U)。
RetractableTopNFunction 中有如下属性,记录相同的 RowData 列表,使用 sortedMap 来进行 TopN 排序:
1 | // a map state stores mapping from sort key to records list |
RetractableTopNFunction 中的 processElement() 方法,按照数据的 RowKind 分别执行 emit 和 retract 操作:
1 |
|
RetractableTopNFunction 中的 emitRecordsWithRowNumber() 方法正常输出排序行:
1 | private void emitRecordsWithRowNumber( |
RetractableTopNFunction 中的 retractRecordWithRowNumber() 方法将撤回行从 sortedMap 中移除,并更新前一行的排位输出:
1 | private void retractRecordWithRowNumber( |
RetractableTopNFunctionTest
1 |
|
输出结果如下:
1 | Output element -> +I{row1=+I(book,1,12), row2=+I(1)} |
UpdatableTopNFunction
支持更新流,是 RetractableTopNFunction 的简单实现版本,输入流中不能包含 DELETE 和 UPDATE_BEFORE 操作。
UpdatableTopNFunctionTest
1 | /** |
输出结果如下:
1 | Output element -> +I(book,2,19) |