量身定制的序列化框架
直接操作二进制数据
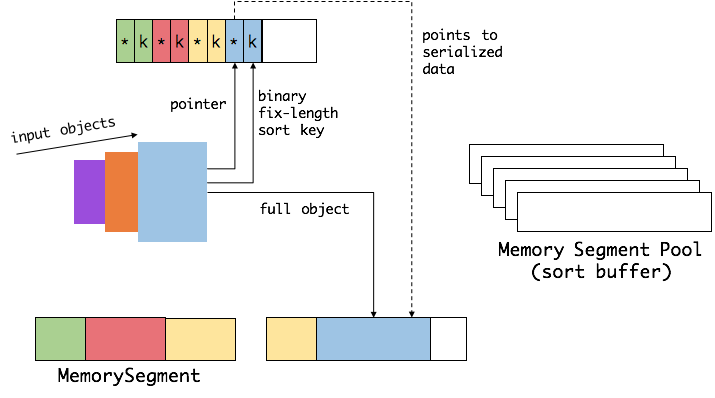
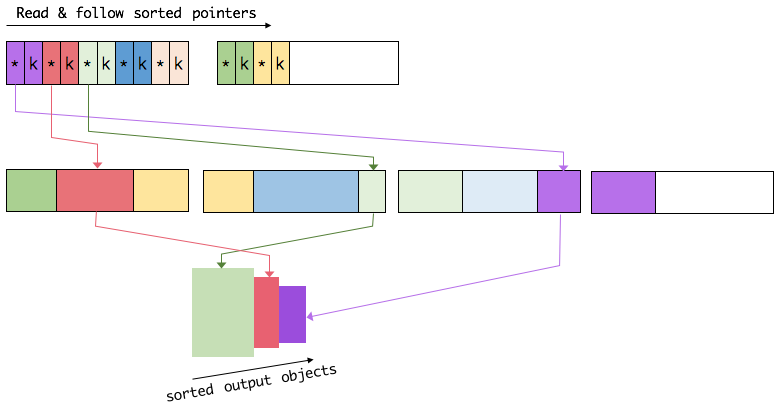
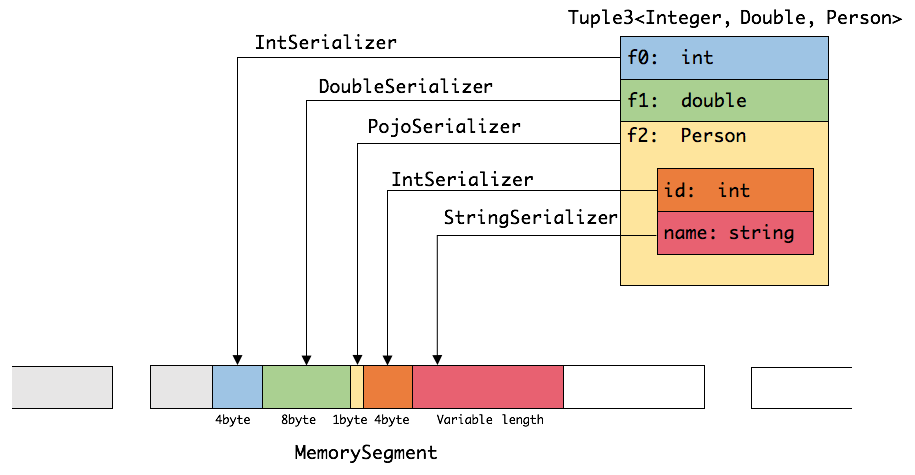
Flink通过定制的序列化框架将算法中需要操作的数据(如sort中的key)连续存储,而完整的数据存储在其他地方。因为对于完整的数据来说,key+pointer 更容易装进缓存,这大大提高了缓存命中率,从而提高了基础算法的效率。这对于上层应用是完全透明的,可以充分享受缓存友好带来的性能提升。
堆外内存
Flink 基于堆内存的内存管理机制已经可以解决很多 JVM 现存问题了,为什么还要引入堆外内存?
启动超大内存(上百 GB)的 JVM 需要很长时间,GC 停留时间也会很长(分钟级)。使用堆外内存的话,可以极大地减小堆内存(只需要分配 Remaining Heap 那一块),使得 TaskManager 扩展到上百 GB 内存不是问题。
高效的 IO 操作。堆外内存在写磁盘或网络传输时是 zero-copy,而堆内存的话,至少需要 copy 一次。
堆外内存是进程间共享的。也就是说,即使 JVM 进程崩溃也不会丢失数据。这可以用来做故障恢复(Flink 暂时没有利用起这个,不过未来很可能会去做)。
Flink用通过ByteBuffer.allocateDirect(numBytes)来申请堆外内存,用 sun.misc.Unsafe 来操作堆外内存。
基于 Flink 优秀的设计,实现堆外内存是很方便的。Flink 将原来的 MemorySegment 变成了抽象类,并生成了两个子类。HeapMemorySegment 和 HybridMemorySegment。从字面意思上也很容易理解,前者是用来分配堆内存的,后者是用来分配堆外内存和堆内存的。是的,你没有看错,后者既可以分配堆外内存又可以分配堆内存。为什么要这样设计呢?
首先假设HybridMemorySegment只提供分配堆外内存。在上述堆外内存的不足中的第二点谈到,Flink 有时需要分配短生命周期的 buffer,这些 buffer 用HeapMemorySegment会更高效。那么当使用堆外内存时,为了也满足堆内存的需求,我们需要同时加载两个子类。这就涉及到了 JIT 编译优化的问题。因为以前 MemorySegment 是一个单独的 final 类,没有子类。JIT 编译时,所有要调用的方法都是确定的,所有的方法调用都可以被去虚化(de-virtualized)和内联(inlined),这可以极大地提高性能(MemroySegment的使用相当频繁)。然而如果同时加载两个子类,那么 JIT 编译器就只能在真正运行到的时候才知道是哪个子类,这样就无法提前做优化。实际测试的性能差距在 2.7 被左右。