本文介绍Netty内存池化管理。
Netty内存池化管理
PooledBufferAllocator
PoolThreadCache
Netty自己实现了类似LocalThread的类来充当线程缓存
PoolThreadLocalCache 继承自 FastThreadLocal
JEMalloc分配算法
PoolArena
Netty内存主要分为两种:DirectByteBuf 和 HeapByteBuf。Netty作为服务器架构技术,拥有大量的网络数据传输,当我们进行网络传输时,必须将数据拷贝至直接内存,合理利用好直接内存,
能够显著提高性能。
- Pool 和 Unpool的区别
池化内存的管理方式是首先申请一大块内存,当使用完成释放后,再将该部分内存放入池子中,等待下一次的使用,这样的话,可以减少垃圾回收的次数,提高处理性能。
非池化内存就是普通的内存使用,需要时直接申请,释放时直接释放。目前netty针对pool做了大量的支持,这样内存使用直接交给了netty管理,减轻了直接内存回收的压力。
这样的话,内存分为4种: PoolDireBuf、UnpoolDireBuf、PoolHeapBuf、UnpoolHeapBuf。Netty底层默认使用PoolDireBuf类型的内存,这些内存主要由PoolArena管理。
- PoolArena
PoolArena作为Netty底层内存池核心管理类,主要原理是首先申请一些内存块,不同的成员变量来完成不同大小的内存块分配。下图描述了PoolArena最重要的成员变量:
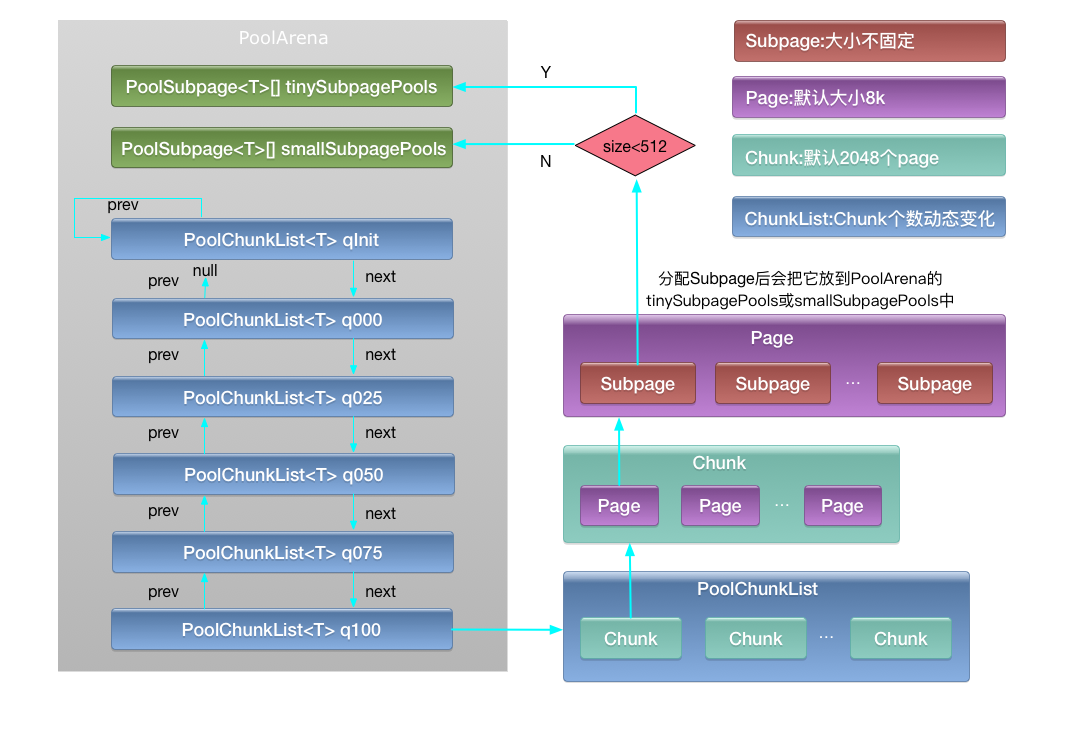
Tiny解决 16b~498b 之间的内存分配,Small解决 512b~4kb 的内存分配,Normal解决 8kb~16mb 的内存分配。
- PoolArena的内存分配
线程分配内存主要从两个地方分配:PoolThreadCache 和 PoolArena
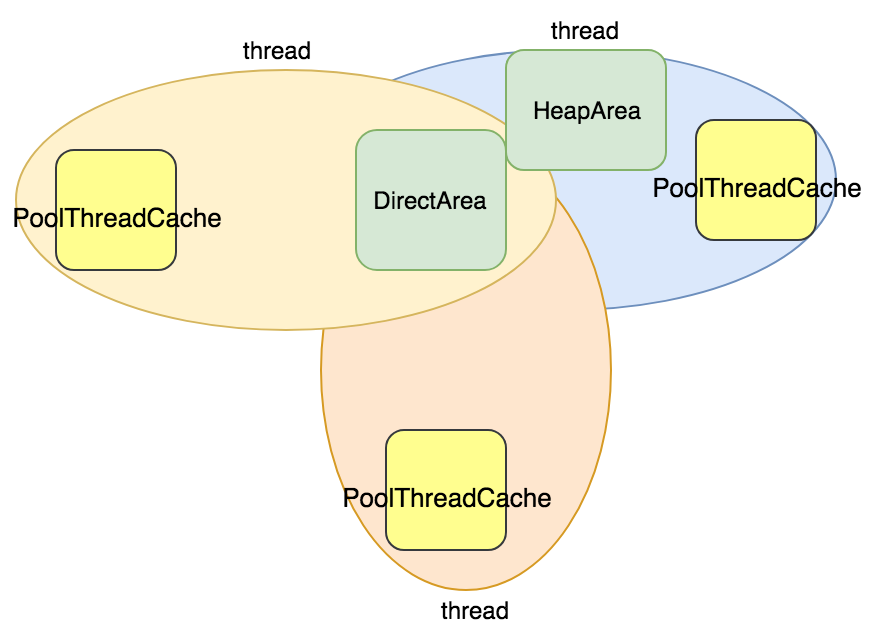
其中 PoolThreadCache 线程独享,PoolArena为几个线程共享。
Netty真正申请内存时的调用过程:
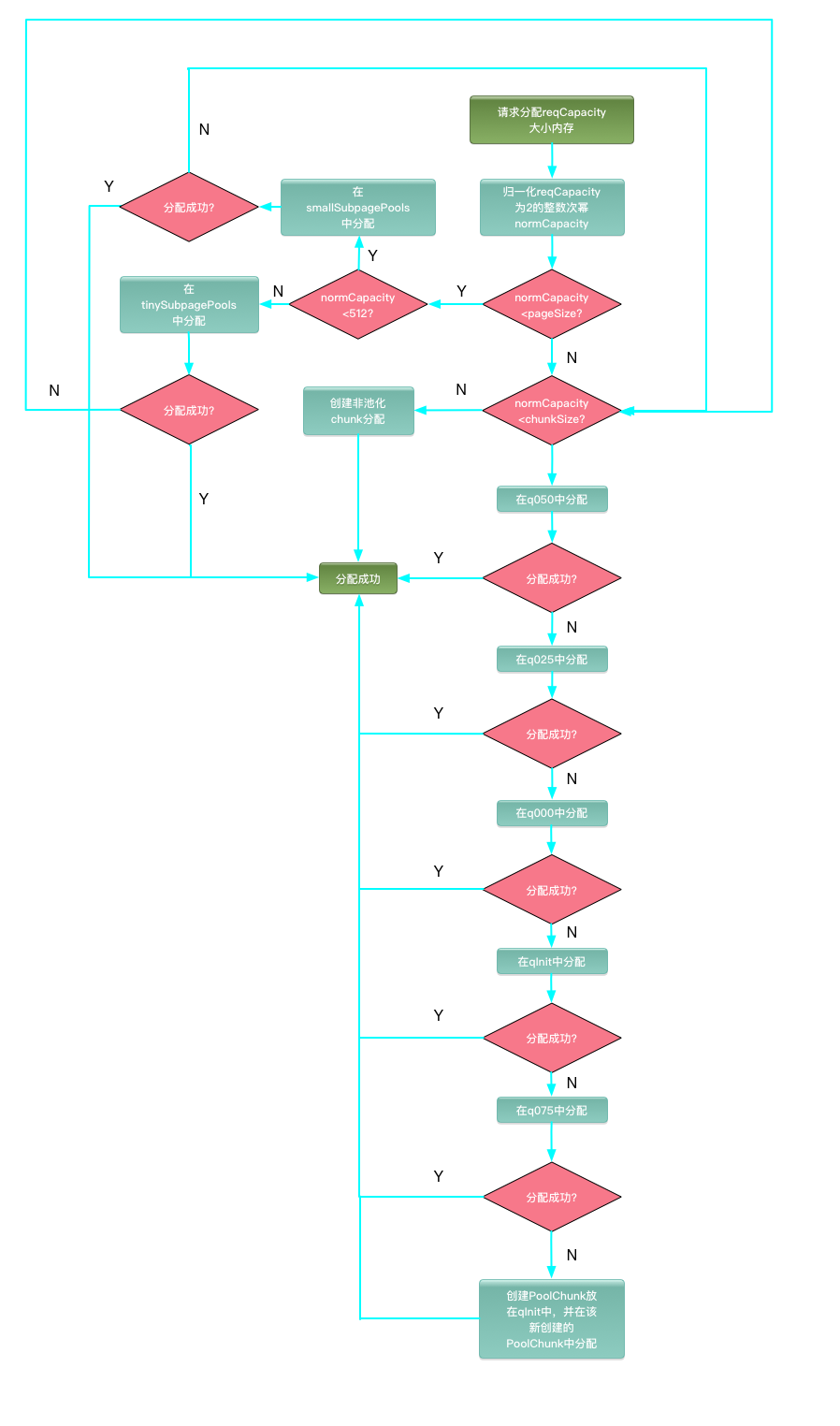
PoolArena.allocate() 分配内存主要考虑先尝试从缓存中,然后再尝试从PoolArena分配。Tiny 和 Small 的申请过程一样,以Tiny申请为例,具体过程如下:
1)对申请的内存进行规范化,就是说只能申请某些固定大小的内存,比如Tiny范围的是16b倍数的内存,Small为512b、1k、2k、4k 的内存,Normal为8k、16k … 16m
范围的内存,始终是2的幂次方。申请的内存不足16b的,按照16b去申请。
2) 判断是否是小于8k的内存申请,若是申请Tiny|Small级别的内存:
首先尝试从cache中申请,申请不到的话,接着会尝试从 tinySubPagePools 中申请,首先计算出该内存在 tinySubPagePools 中对应的下标。
检查对应链串是否已经有PoolSubpage可用, 若有的话, 直接进入PoolSubpage.allocate进行内存分配
若没有可分配的内存, 则会进入allocateNormal进行分配
3)若分配normal类型的类型, 首先也会尝试从缓存中分配, 然后再考虑从allocateNormal进行内存分配。
4)若分配大于16m的内存, 则直接通过allocateHuge()从内存池外分配内存。
PoolChunkList
对于在q050、q025、q000、qInit、q075这些PoolChunkList里申请内存的流程图如下:
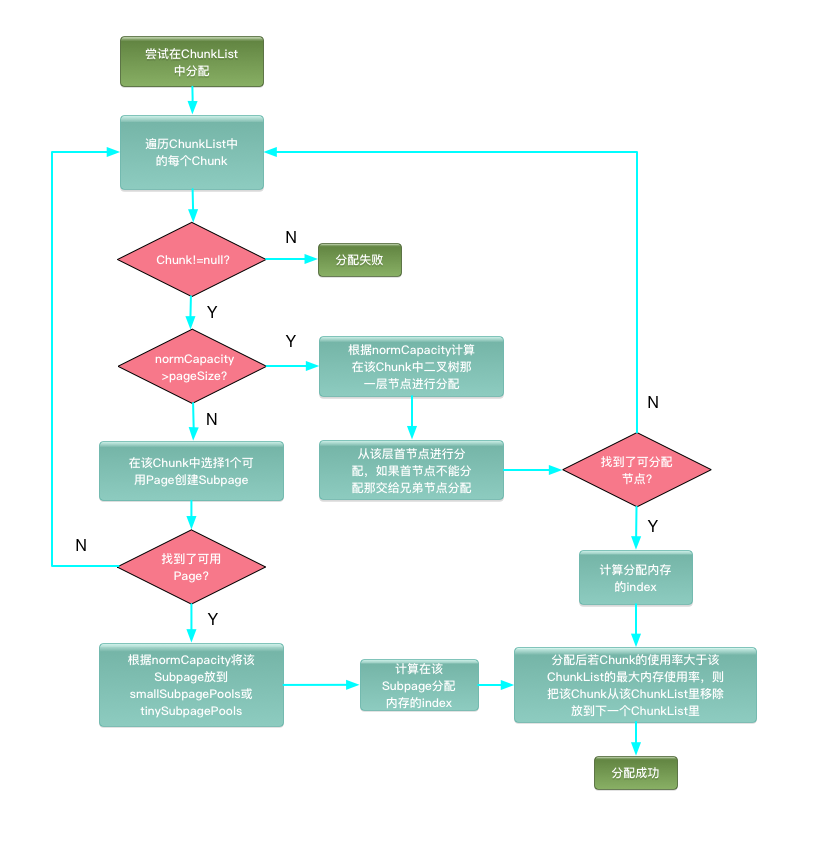
按照以上顺序,这样安排的考虑是:
将PoolChunk分配维持在较高的比例上
保存一些空闲较大的内存,以便大内存的分配
PoolChunk
PoolSubpage
Netty中大于8k的内存都是通过PoolChunk来分配的,小于8k的内存是通过PoolSubpage分配的。当申请小于8k的内存时,会分配一个8k的叶子节点,若用不完的话,存在很大的浪费,所以通过
- 双向链表
添加节点:
1 | private void addToPool(PoolSubpage<T> head) { |
双向列表的插入:
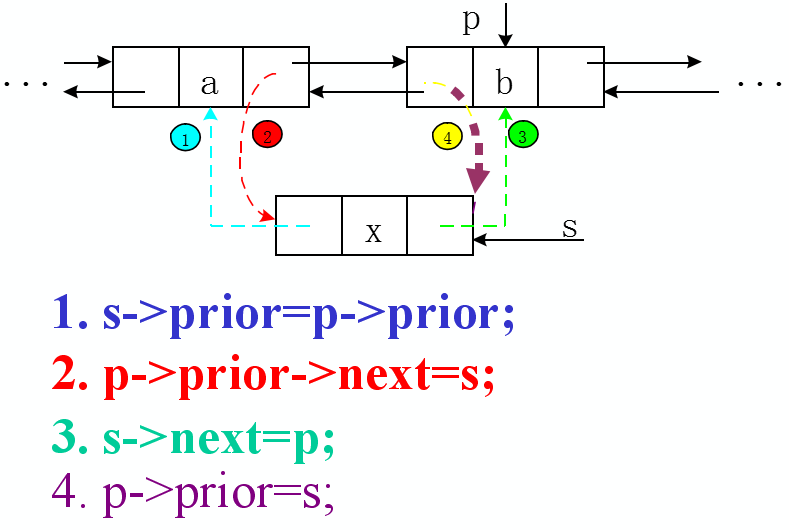
第一步:首先找到插入位置,节点 s 将插入到节点 p 之前
第二步:将节点 s 的前驱指向节点 p 的前驱,即 s->prior = p->prior;
第三步:将节点 p 的前驱的后继指向节点 s 即 p->prior->next = s;
第四步:将节点 s 的后继指向节点 p 即 s->next = p;
第五步:将节点 p 的前驱指向节点 s 即 p->prior = s;
移除节点:
1 | private void removeFromPool() { |
双向列表的删除:
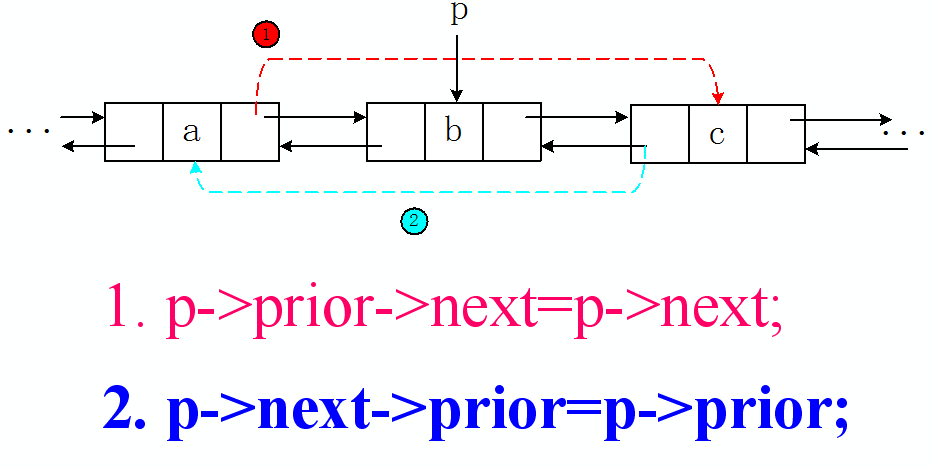
第一步:找到即将被删除的节点 p
第二步:将 p 的前驱的后继指向 p 的后继,即 p->prior->next = p->next;
第三步:将 p 的后继的前驱指向 p 的前驱,即 p->next->prior = p->prior;
第四步:删除节点 p 即 delete p;
PoolSubpage 管理8k的内存,如下图:
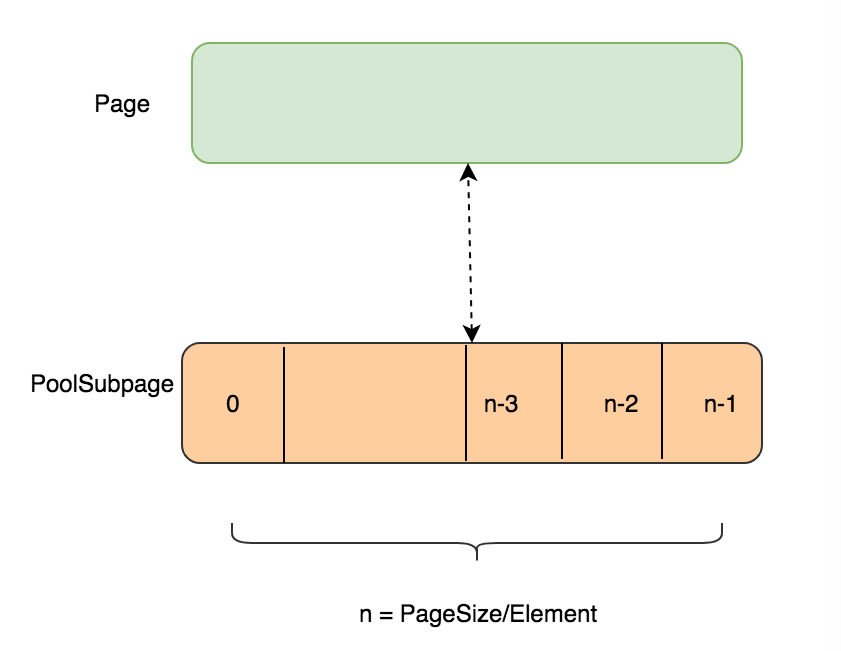
每一个PoolSubpage都会与PoolChunk里面的一个叶子节点映射起来。
1.首次请求Arena分配,Arena中的双向链表为空,不能分配;
2.传递给Chunk分配,Chunk找到一个空闲的Page,然后均等切分并加入到Arena链表中,最后分配满足要求的大小。
之后请求分配同样大小的内存,则直接在Arena中的PoolSubpage双向链表进行分配;如果链表中的节点都没有空间分配,则重复1步骤。
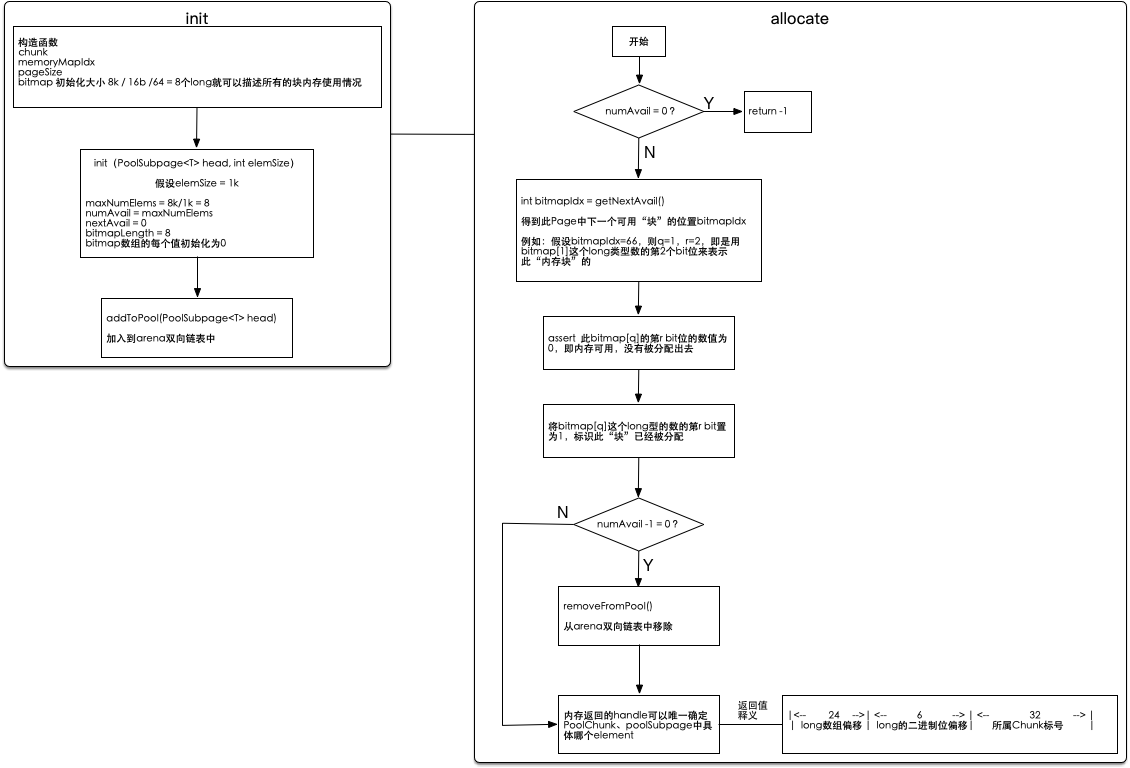
Netty使用一个long整型表示在 PoolSubpage 中的分配结果,高32位表示均等切分小块的块号,其中的低6位用来表示64位即一个long的分配信息,其余位用来表示long数组的索引。低32位表示所属Chunk号。
以下是PoolSubpage的init及allocate流程图:
DirectByteBuffer
我们知道, 在使用IO传输数据时, 首先会将数据传输到堆外直接内存中, 然后才通过网络发送出去。这样的话, 数据多了次中间copy, 能否不经过copy而直接将数据发送出去呢, 其实是可以的, 存放的位置就是本文要讲的主角:DirectByteBuffer 。
JVM内存主要分为heap内存和堆外内存(一般我们也会称呼为直接内存), heap内存我们不用care, jvm能自动帮我们管理, 而堆外内存回收不受JVM GC控制, 因此, 堆外内存使用必须小心。