Flink SQL 使用 Apache Calcite 并对其扩展以支持 SQL 语句的解析与验证。
目前 Calcite 流处理语句已实现对 SELECT, WHERE, GROUP BY, HAVING, UNION ALL, ORDER BY 以及 FLOOR, CEIL 函数的支持。
本文将以代码的形式说明 Flink SQL 是如何解析 DDL 语句,javacc 与 java 语言之间的转换关系。
Flink SQL 解析的代码参考:Flink SQL 解析
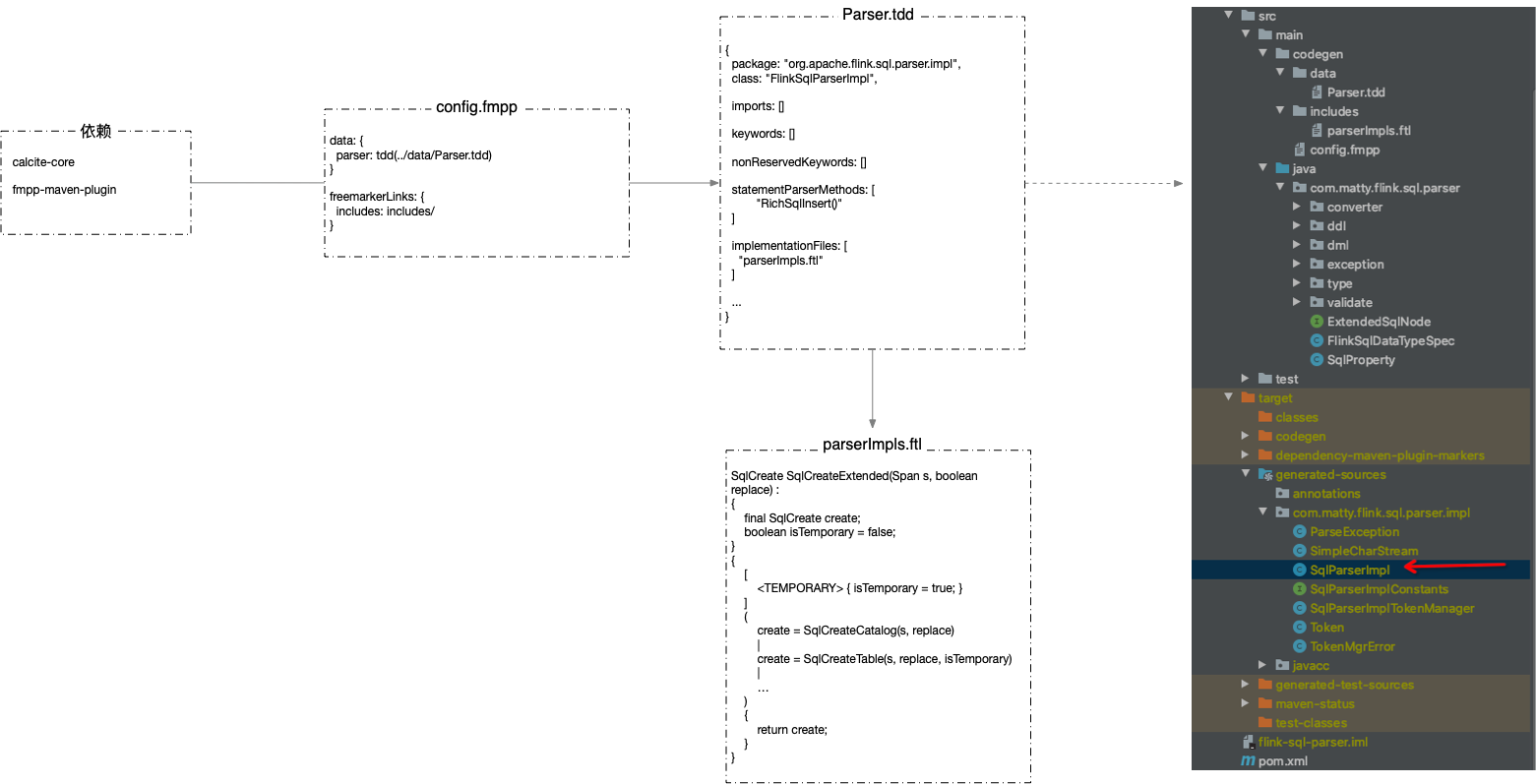
工程结构
sql-parser 的工程结构,如图所示:
1 | <dependency> |
config.mpp
1 | # |
Parser.tdd
1 | { |
以下结合 Parser.tdd 文件和 calcite-core jar包中打进去的 Parser.jj文件结合说明。
packge,class,imports
主要是负责导入包,设置编译package目录,编译的类名:
1 | PARSER_BEGIN(${parser.class}) |
keywords
定义关键字:
1 | <DEFAULT, DQID, BTID> TOKEN : |
nonReservedKeywords
keywords定义关键字中,非保留的关键字:
1 | String NonReservedKeyWord() : |
joinTypes
join类型:
1 | SqlLiteral JoinType() : |
statementParserMethods
解析自定义SQL语句的方法列表,必须继承SqlNode:
1 | /** |
literalParserMethods
解析自定义文字的方法列表,必须实现SqlNode:
1 | SqlNode Literal() : |
dataTypeParserMethods
解析自定义数据类型的方法列表,必须实现SqlIdentifier:
1 | // Some SQL type names need special handling due to the fact that they have |
alterStatementParserMethods
解析自定义alter语句,必须有构造方法 (SqlParserPos pos, String scope):
1 | /** |
createStatementParserMethods
解析自定义create语句,必须有构造方法 (SqlParserPos pos, String scope):
1 | <#if parser.createStatementParserMethods?size != 0> |
dropStatementParserMethods
解析自定义drop语句,必须有构造方法(SqlParserPos pos):
1 | <#if parser.dropStatementParserMethods?size != 0> |
implementationFiles
自定义模板文件:
1 | <#-- Add implementations of additional parser statement calls here --> |
includeCompoundIdentifier
是否包含CompoundIdentifier解析
Parser.jj常用方法
getPos
获取当前token的位置,自定义解析时使用
StringLiteral
解析语句中的string类型的字段,带’’
1 | select * from table where a='string'; |
Identifier
解析Identifier字段,返回string类型
1 | select Identifier from table; |
可以有SimpleIdentifier,可以是表名、字段名、别名等
或CompoundIdentifier,如要解析kafka.bootstrap.servers这样的复合字符串
以下介绍真正运用在Flink SQL解析的示例:
DDL
CREATE TABLE
自定义SQL语法
自定义SQL DDL语句,创建source表、维表、sink表。下面给出几种常见的建表sql示例:
创建kafka source表,带计算列和watermark的定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15CREATE TABLE table_source(
channel varchar, -- 频道
pv int, -- 点击次数
xctime varchar, -- yyyyMMddHHmmss格式时间戳,字符串类型
ts AS TO_TIMESTAMP(xctime,'yyyyMMddHHmmss'), -- rowtime,必须为Timestamp类型或Long类型
WATERMARK FOR ts AS withOffset( ts , '120000' ) --watermark计算方法,允许2分钟的乱序时间,即允许数据迟到2分钟
)WITH(
type='kafka11',
kafka.bootstrap.servers='mwt:9092',
kafka.auto.offset.reset='latest',
kafka.kerberos.enabled='false',
kafka.data.type='json',
kafka.topic='table_source',
parallelism='1'
)创建mysql维表
1
2
3
4
5
6
7
8
9
10
11
12
13
14CREATE TABLE table_side(
name varchar comment '名称', -- 允许给字段设置comment
info varchar comment '详细信息',
PRIMARY KEY(name), -- 创建维表一定要指定 PRIMARY KEY
PERIOD FOR SYSTEM_TIME -- 维表标识
)WITH(
type ='mysql',
url ='jdbc:mysql://192.168.1.8:3306/demo?charset=utf8',
userName ='dipper',
password ='ide@123',
tableName ='table_side',
cache ='NONE',
parallelism ='1'
)创建sink表
1
2
3
4
5
6
7
8
9
10CREATE TABLE table_sink(
name varchar,
channel varchar,
pv int,
xctime bigint,
info varchar
)WITH(
type ='console',
parallelism='1'
);
语句执行流程
1 |
|
定义解析结果类
1 | package com.matty.flink.sql.parser.ddl; |
1 |
|
javacc语法模板
SqlCreateTable
1 | /** |
对应生成的 SqlParserImpl 类中,从 SqlStmt() 方法为切入口:
- 首先定位到 token - “CREATE”
- 定位到 token - “TABLE”
- 定位到 token - “table_source”
- 定位到 token - “(“
- 解析 “(“ 后设置的多个 TableColumn ,涉及到普通字段、主键、watermark、维表标记解析,设置到 TableCreationContext 中
单个 column 解析交给TableColumn(ctx)方法执行; - 定位到 token - “)”
- 定位到 token - “COMMENT”
- 定位到 token - “WITH”,交给
TableProperties()方法处理 - 返回 java 对象
SqlCreateTable
- 返回 java 对象
1 | public class SqlParserImpl extends SqlAbstractParserImpl implements SqlParserImplConstants { |
TableColumn
将 TableCreationContext 作为参数传递给 TableColumn,解析得到的结果都会设置到 TableCreationContext 类中。分别会解析字段列、主键信息、计算列、watermark 标识、维表标识。
1 | /** |
- TableColumn2
解析建表语句的字段值,类型为自定义的 FlinkSqlDataTypeSpec
1 | void TableColumn2(List<SqlNode> list) : |
处理表列,从 TableColumn() 方法为切入口:
- 处理普通列字段,交给
TableColumn2(context.columnList)方法处理 - 处理主键字段,交给
PrimaryKey()方法处理 - 处理 watermark 字段,交给
Watermark(context)方法处理 - 处理计算列,交给
ComputedColumn(context)方法处理 - 处理维表标记,交给
SideFlag()方法处理
处理表的普通列,从 TableColumn2() 方法为切入口:
- 获取列名
- 解析列类型,
FlinkDataType,flink 自定义的数据类型 - 读取 token - “AS” 及 alias
- 读取字段描述
- 返回表列对应的 java 对象
SqlTableColumn
1 | public class SqlParserImpl extends SqlAbstractParserImpl implements SqlParserImplConstants { |
FlinkDataType
Flink Sql有许多自定义类型
1 | /** |
PrimaryKey
解析主键信息,主键字段可能有多个,如 PRIMARY KEY(id,name)
1 | /** |
处理主键,从 PrimaryKey() 方法为切入口:
- 获取 token - “PRIMARY”
- 获取 token - “KEY”
- 获取 token - “(“
- 获取主键列名称,加入 pkList ,多个列以逗号间隔
- 返回一个 SqlNodeList 对象
1 | public class SqlParserImpl extends SqlAbstractParserImpl implements SqlParserImplConstants { |
Watermark
解析watermark,事件时间窗口需要使用 watermark,如:WATERMARK FOR ts AS withOffset( ts , '120000' )
1 | void Watermark(TableCreationContext context) : |
处理 watermark ,从 Watermark(context) 方法为切入口:
- 获取 token - “WATERMARK”
- 获取 token - “FOR”
- 获取 EventTime 字段名称
- 获取 token - “AS”
- 获取 token - “withOffset”
- 获取 token - “(“
- 再次获取 EventTime 字段名称
- 获取 token - “,”
- 获取允许延迟的 ms 值
- 获取 token - “)”
1 | public class SqlParserImpl extends SqlAbstractParserImpl implements SqlParserImplConstants { |
ComputedColumn
解析计算列,如:ts AS TO_TIMESTAMP(xctime,'yyyyMMddHHmmss')
1 | void ComputedColumn(TableCreationContext context) : |
处理计算列,从 ComputedColumn(context) 方法为切入口:
- 获取计算列名
- 获取 token - “AS”
1 | public class SqlParserImpl extends SqlAbstractParserImpl implements SqlParserImplConstants { |
SideFlag
解析维表标识,如果为true,说明创建的是维表
1 | /** |
TableProperties
解析出WITH参数列表
1 | /** |
可自定义字段类型
- FlinkSqlDataTypeSpec
SqlBytesType
1 | SqlIdentifier SqlBytesType() : |
1 | public class SqlBytesType extends SqlIdentifier implements ExtendedSqlType{ |
SqlStringType
1 | SqlIdentifier SqlStringType() : |
1 | public class SqlStringType extends SqlIdentifier implements ExtendedSqlType { |
SqlArrayType
1 | SqlIdentifier SqlArrayType() : |
1 | public class SqlArrayType extends SqlIdentifier implements ExtendedSqlType { |
SqlMultisetType
1 | SqlIdentifier SqlMultisetType() : |
1 | public class SqlMultisetType extends SqlIdentifier implements ExtendedSqlType{ |
SqlMapType
1 | SqlIdentifier SqlMapType() : |
1 | public class SqlMapType extends SqlIdentifier implements ExtendedSqlType{ |
SqlRowType
1 | /** |
1 |
|
SqlTimeType
1 | SqlIdentifier SqlTimeType() : |
1 | public class SqlTimeType extends SqlIdentifier implements ExtendedSqlType { |
SqlTimestampType
1 | SqlIdentifier SqlTimestampType() : |
1 | public class SqlTimestampType extends SqlIdentifier implements ExtendedSqlType { |
测试使用
1 |
|
CREATE VIEW 和 CREATE FUNCTION 操作类似,具体参考示例代码。
CREATE VIEW
- SQL语法
1 | CREATE VIEW table_sink_view AS |
- javacc语法模板
1 | /** |
CREATE FUNCTION
- SQL语法
1 | CREATE FUNCTION StringLengthUdf AS 'com.dtwave.example.flink.udx.udf.StringLengthUdf'; |
- javacc语法模板
1 | /** |